
Machine learning techniques such as Convolutional Neural Networks have become state-of-the-art for interpretation and automatic annotation of various data. However, these methods often require huge amounts of labeled data (“Ground Truth”). Especially in the domain of geospatial data analysis such datasets are scarce. Commonly, labels are collected by experts, but since the labeling process is very time-consuming, this approach causes tremendous costs and might not be feasible.
Hence, the focus of this research lies in outsourcing this tedious and costly task to the crowd (“Crowdsourcing”), which is composed of people from various countries, with different cultural backgrounds and different abilities. Therefore, a very inhomogeneous quality is to be expected. Hence, methods of quality control are crucial when using this data as training data for machine learning algorithms.
As already demonstrated in various studies, one remedy is the “Wisdom of the Crowd”. This means, that a large pool of humans is able of doing tasks one individual is not capable of by combining the strengths of all workers of the crowd. The easiest realization of this technique is Majority Vote.
Although this approach can lead to high-quality results, we need to conduct multiple acquisitions by different crowdworkers. While it is one goal of this research topic to determine the amount of required multiple acquisitions, we aim at minimizing the total labeling effort. For this purpose we combine both the strengths of machine learning techniques and human perception. In this context, Active Learning strategies can be applied, where the machine queries for most informative instances, so that human labeling effort can be deployed purposefully by focusing on these samples.
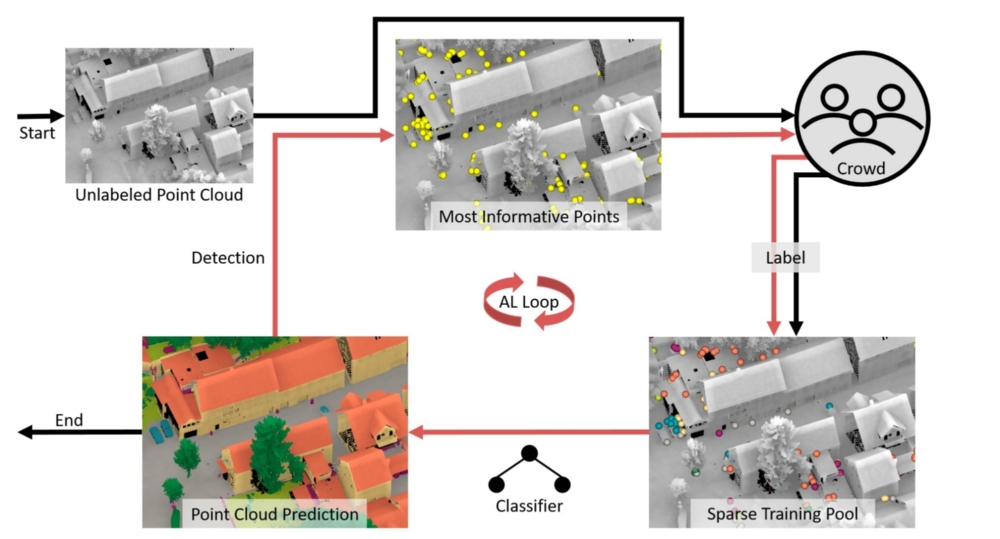
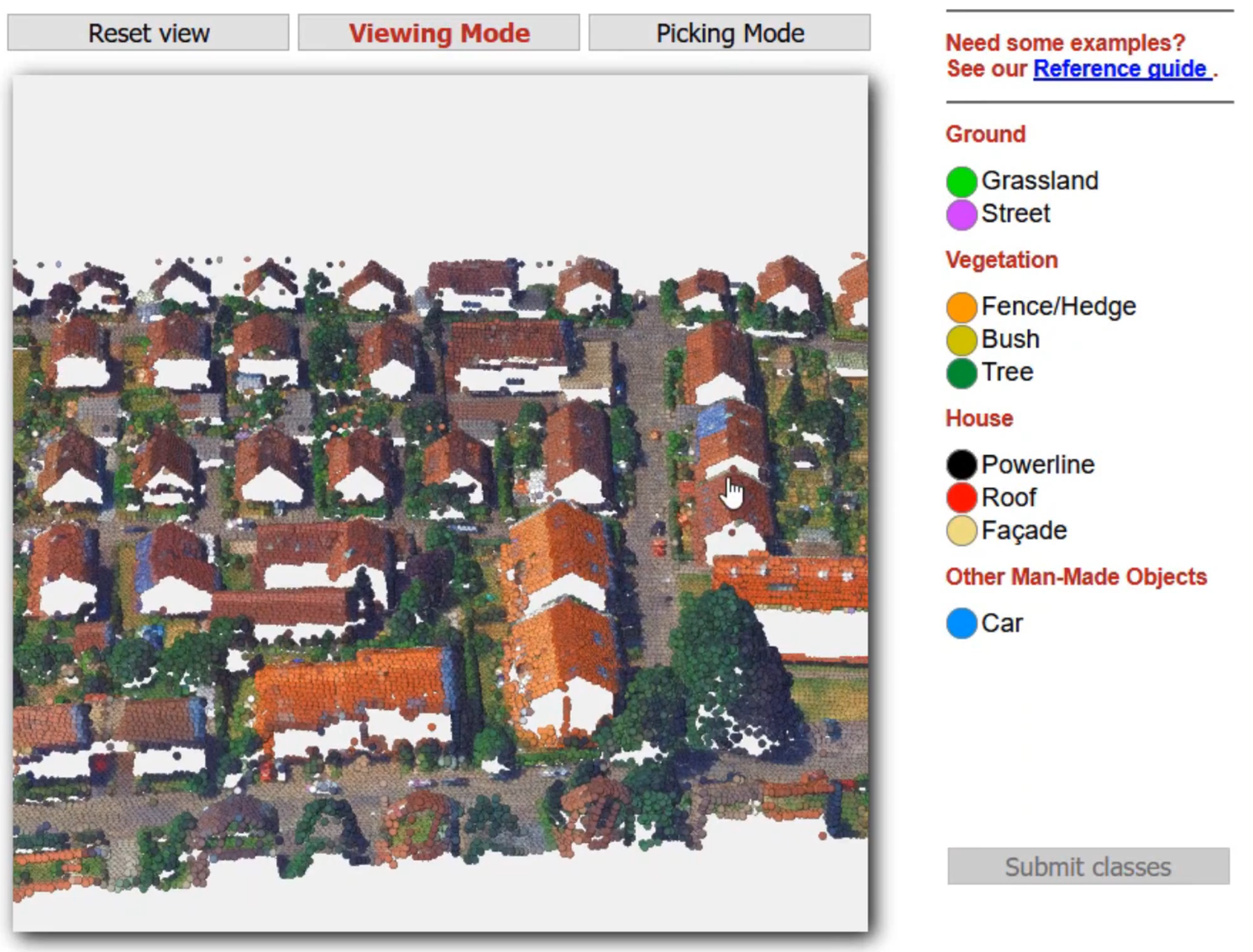
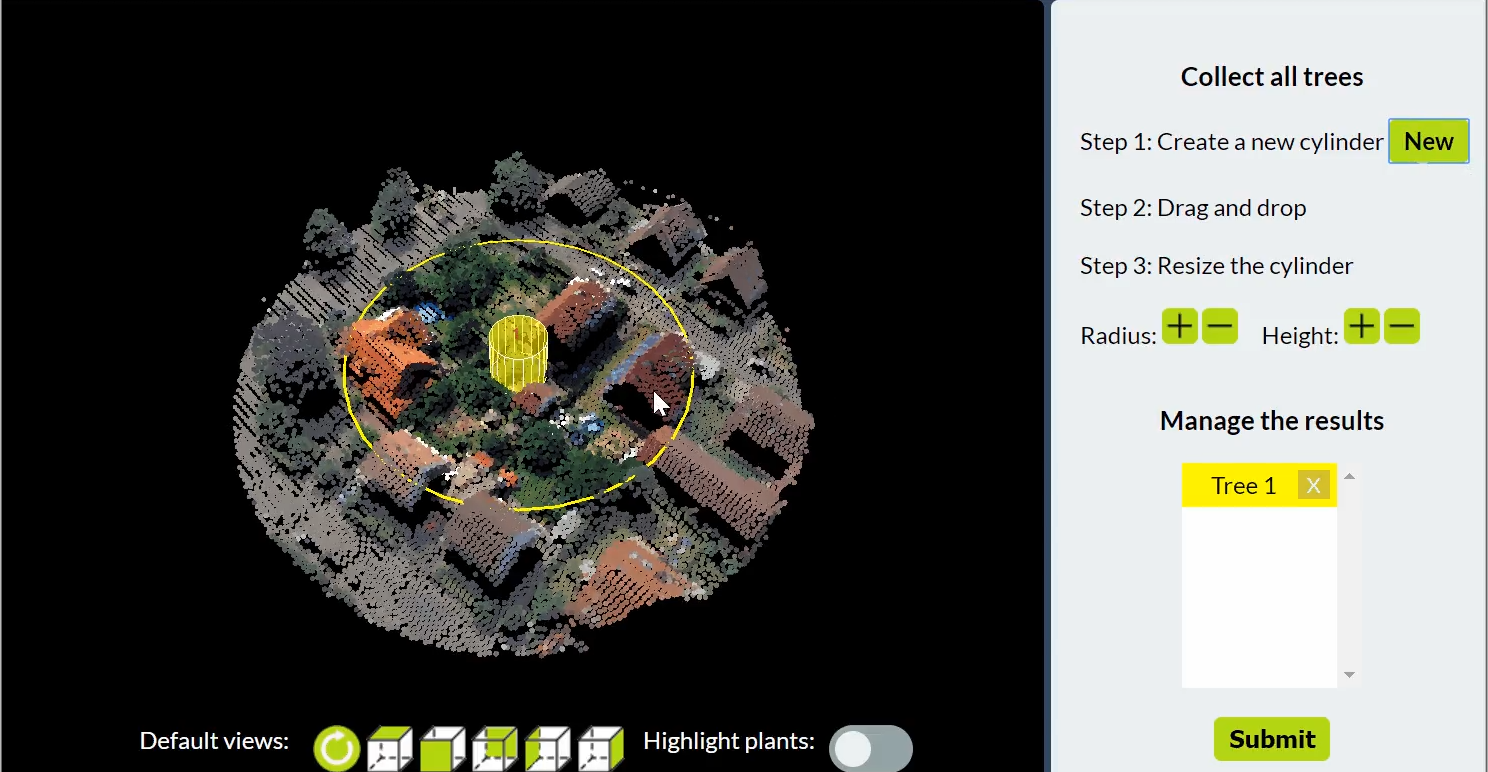
In order to reach a vast pool of potential workers and acquire labels, web-based tools are employed for presenting data and enabling the crowd to contribute. While it is our goal to collect labels for multiple data representations by the crowd such as imagery, 3D point clouds and 3D meshes, we are further investigating which representation is best suited for the acquisition of labels by the crowd.
Try out one of our web tools here
{kind=link}
{kind=link}

ifp publications
Please also refer to our YouTube channel
Walter, V.; Koelle, M. & Collmar, D. [2022]
A Gamification Approach for the Improvement of Paid Crowd-based Labelling of Geospatial Data. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-4-2022, 113–120, 2022.
DOI: 10.5194/isprs-annals-V-4-2022-113-2022
Koelle, M.; Walter, V. & Soergel, U. [2022]
Learning from the Past: Crowd-driven Active Transfer Learning for Semantic Segmentation of Multi-Temporal 3D Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-2-2022, 259–266, 2022.
DOI: 10.5194/isprs-annals-V-2-2022-259-2022
Walter, V.; Koelle, M. & Collmar, D. [2022]
Measuring the Wisdom of the Crowd: How Many is Enough?. PFG – Journal of Photogrammetry, Remote Sensing and Geoinformation Science, 2022.
DOI: 10.1007/s41064-022-00202-2
Walter, V.; Koelle, M.; Collmar, D. & Zhang, Y. [2021]
A Two-Level Approach for the Crowd-Based Collection of Vehicles from 3D Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-4-2021, 97–104, 2021.
DOI: 10.5194/isprs-annals-V-4-2021-97-2021
Koelle, M.; Laupheimer, D.; Walter, V.; Haala, N. & Soergel, U. [2021]
Which 3D Data Representation Does the Crowd Like Best? Crowd-Based Active Learning for Coupled Semantic Segmentation of Point Clouds and Textured Meshes. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-2-2021, 93–100, 2021.
DOI: 10.5194/isprs-annals-V-2-2021-93-2021
Koelle, M.; Walter, V.; Schmohl, S.; Soergel U. [2021]
Remembering Both the Machine and the Crowd When Sampling Points: Active Learning for Semantic Segmentation of ALS Point Clouds. In: Del Bimbo A. et al. (eds) Pattern Recognition. ICPR International Workshops and Challenges. ICPR 2021. Lecture Notes in Computer Science, vol 12667. Springer, Cham.
DOI: 10.1007/978-3-030-68787-8_37
Koelle, M.; Walter, V.; Shiller, I.; Soergel U. [2021]
CATEGORISE: An Automated Framework for Utilizing the Workforce of the Crowd for Semantic Segmentation of 3D Point Clouds. In: Bauckhage C. et al. (eds) Pattern Recognition. GCPR 2021. Lecture Notes in Computer Science, vol 13024. Springer, Cham.
DOI: 10.1007/978-3-030-92659-5_41
Walter, V.; Koelle, M. & Yin, Y. [2020]
Evaluation and Optimisation of Crowd-based Collection of Trees from 3D Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-4-2020, 49-56, 2020.
DOI: 10.5194/isprs-annals-V-4-2020-49-2020
Koelle, M.; Walter, V.; Schmohl, S. & Soergel, U. [2020]
Hybrid Acquisition of High Quality Training Data for Segmentation of 3D Point Clouds Using Crowd-based Active Learning. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., V-2-2020, 501-508, 2020.
DOI: 10.5194/isprs-annals-V-2-2020-501-2020
Walter, V. & Soergel, U. [2018]
Results and Problems of paid Crowd-based geospatial Data Collection. PFG – Journal of Photogrammetry, Remote Sensing and Geoinformation Science. pp 1-11.
DOI: 10.1007/s41064-018-0058-z
Walter, V.; Laupheimer, D. & Fritsch, D. [2016]
Use and Optimization of Paid Crowdsourcing for the Collection of Geodata. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLI-B4, pp. 253-257.
DOI: 10.5194/isprs-archives-XLI-B4-253-2016

Volker Walter
Dr.-Ing.Head of Research Group Geoinformatics

Michael Kölle
M.Sc.Research Associate