The internet contains huge amounts of maps representing almost every part of the Earth in many different scales and map types. However, this enormous quantity of information is completely unstructured and it is very difficult to find a map of a specific area and with certain content, because the map content is not accessible by search engines in the same way as web pages. However, searching with search engines is at the moment the most effective way to retrieve information in the internet and without search engines most information would not be findable. In order to overcome this problem, methods are needed to search automatically for maps in the internet and to make the implicit information of maps explicit so that it can be processed by machines.
The search for specific file types which contain spatial data is only restricted possible with existing search engines. Many search engines do not support the search for specific file types at all, such as Microsoft Bing or Lycos. Other search machines support the search for specific file types, but only for a limited set of file types. For example, Google support the search for the file types: pdf, ps, dwf, kml, kmz, xls, ppt, rtf and swf. Although the file types kml and kmz represent geographical features, in most of all cases they contain only the coordinates of points of interest and not comprehensive map data. In contrast, Esri Shapefile (shp) is a very popular geospatial vector data format for geographic information and a huge amount of maps in shape format are available in the internet. Since commercial search engines do not support the search for Shapefiles, we developed a web crawler for this task. A web crawler is a computer program that browses the World Wide Web in a systematical way. A web crawler starts at a predefined web page and extracts all links of this page. Then, the web crawler follows the links and again extracts the links of the linked web pages. This is repeated until a break criterion is reached or the whole World Wide Web is retrieved. The visited pages are stored in a database to avoid that a link that has already been followed is used again.
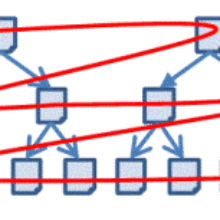
Different strategies can be used to optimize the search result of a web crawler: depth-first search, breadth-first search and best-first search (see Figure 1). In depth-first search, the web crawler starts at a predefined page, extracts the links of this page and follows the first link. Again the links are extracted and the first link is followed. This is repeated until no new link can be found. The next link, which is used, is the second link of the first page. In breath-first search, the web crawler also starts at a predefined page and extracts the links of this page. Each link is followed and all links of the next level are extracted. These links are again followed and all links of the next level are extracted, etc. In best-first search, the links are ranked according to a measure which quantifies the relevance of the links. With this strategy it is possible to find relevant pages faster, but the definition of an appropriate measure is often very difficult.
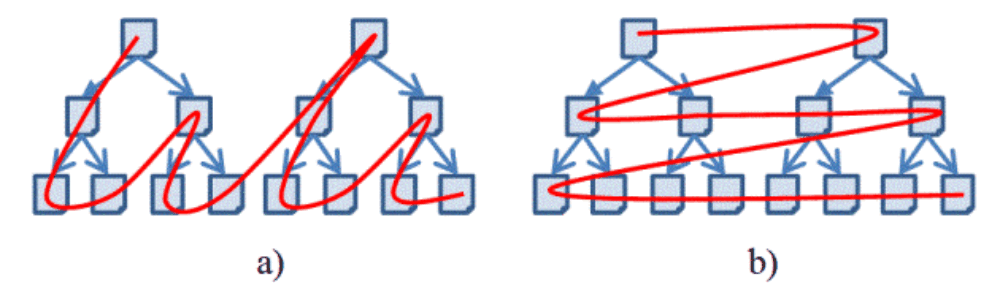
Since the World Wide Web contains an enormous amount of pages, it is not possible to retrieve the whole Web with one single web crawler. For this reason we have developed an alternative strategy to decrease the search space. First, we search for a specific textual search term (for example: "Shapefile download") with Google. Then, the web crawler retrieves only the web pages of the corresponding result list. The web pages are retrieved with a breadth-first search which evaluates only the first three link levels, since we assume that the web page contains a direct link to a Shapefile or an indirect link which can be accessed by following maximum two links. Additionally we evaluate maximum 30,000 links at one server. This avoids that web servers with a huge amount of web pages are completely evaluated, such as Wikipedia. Since Wikipedia is a very popular web site, web pages of Wikipedia are very often at the top in the result list of a Google search.
Shapefiles in the internet can be found normally only in zip-archives, since the information of an ArcGIS geodatabase is normally stored in different files which must be used together (e.g. shp-file contains the geometrical data, dbf-file contains the thematic data, shx-file contains a positional index and prj-file contains coordinate system and projection information). Therefore the web crawler searches for zip-files, extracts the content of the zip-file and then searches for Shapefiles.
We tested our approach with different configurations: (1) a normal breath-search without any limitations and without using a Google result list (the entry point of the web crawler was the homepage of the Institute for Photogrammetry: www.ifp.uni-stuttgart.de) and (2)-(4) with the described strategy and using a Google result list with the search terms (2) " Shapefile download", (3) " Shapefile free" and (4) " Shapefile". The web crawler retrieved exactly 300.000 web pages for all strategies. Table 1 shows the results of the different searches.
| Strategy | Number of visited servers | zip files | shp files | hit rate | |
|---|---|---|---|---|---|
| breadth-search | 9 | 23 | 0 | 0.00% | |
| "Shapefile download" | 33 | 25 188 | 4 594 | 1.53% | |
| "Shapefile free" | 18 | 12 264 | 629 | 0.20% | |
| "Shapefile" | 14 | 2 992 | 528 | 0.18% | |
| Table 1: Results of different search strategies. | |||||

David Collmar
M.Sc.Head of Research Group Geoinformatics