
Abhishek Kaushik
Stabilizing SLAM Algorithm via Semantic Segmentation for Movable Objects Detection
Duration: 6 months
Completition: January 2024
Supervisor: Dr.-Ing. Dominik Laupheimer, MSc David Skuddis, Prof. Dr.-Ing. Norbert Haala
Examiner: Prof. Dr.-Ing. Norbert Haala, Prof. Dr.-Ing. Bin Yang
Introduction and Motivation
Simultaneous Localization and Mapping (SLAM) is vital in robotics, computer vision, and autonomous systems. It enables devices to map unknown environments while determining their own position in real-time. SLAM has broad applications from self-driving cars to drones and augmented reality.
In SLAM algorithms, LiDAR sensors are commonly used for their accuracy in capturing 3D environment structures. However, dynamic surroundings pose challenges to LiDAR-based SLAM, affecting performance due to issues like data association, dynamic object modeling, real-time processing, and map consistency.
To address dynamic object challenges, deep learning-based 3D semantic segmentation can filter out moving elements from LiDAR point clouds, ensuring precise mapping. This approach enhances accuracy by focusing on stationary elements.
3D semantic segmentation extends 2D semantic segmentation principles to interpret complex 3D environments, crucial for autonomous navigation, augmented reality, urban planning, and robotics. However, obtaining large volumes of annotated data for training is costly and time-consuming, necessitating effective strategies to handle domain shifts for scaled automated driving.
Experiments
Our study focuses on the SemanticSlamantic dataset for semantic segmentation and SLAM applications. However, the dataset lacks semantic labels necessary for supervised neural network training. To overcome this, we utilize the SemanticKITTI dataset, which shares similarities with SemanticSlamantic in being collected in Germany and featuring outdoor scenes. SemanticKITTI offers comprehensive annotations for training neural networks.
We train various neural networks using SemanticKITTI in a supervised manner to learn complex patterns and semantic understanding from the annotated data. These trained models are then applied to infer on the SemanticSlamantic dataset, aiming for robust semantic segmentation and SLAM in a closely related scenario.
Despite similarities, there are differences between the two datasets due to variations in sensor types and mounting configurations. SemanticKITTI uses a Velodyne 64-beam LiDAR sensor mounted on a car with a vertical FOV from 2° to -24.8°. In contrast, SemanticSlamantic employs an Ouster 64-beam LiDAR sensor mounted on various platforms with a wider vertical FOV from -22.5° to +22.5°. These differences require domain adaptation techniques to transfer knowledge effectively between datasets, ensuring the model's performance aligns with SemanticSlamantic's characteristics.
Adopting domain adaptation methods becomes crucial to bridge this gap and enhance the model's performance when applied to SemanticSlamantic, ensuring robust semantic segmentation and SLAM across diverse LiDAR sensor setups and FOV ranges in real-world scenarios.
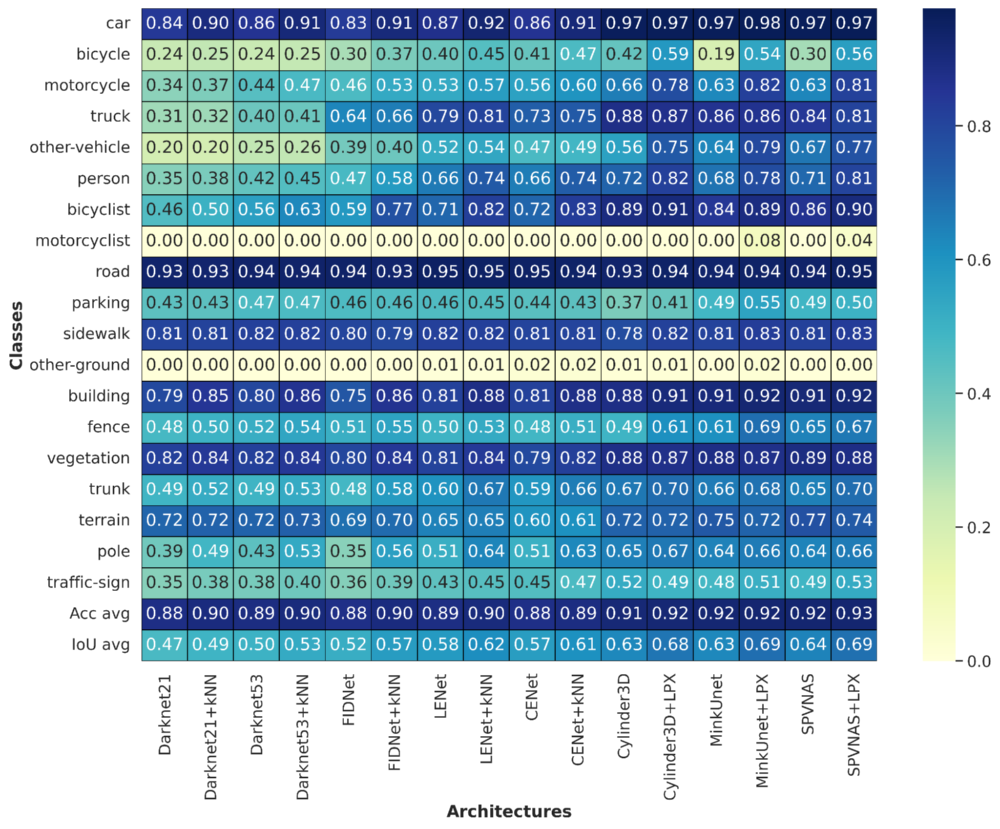
Dynamic Points Filtering

The qualitative analysis sheds light on the performance of the MinkuNet+LPX architecture for dynamic point filtering in semantic segmentation on the SemanticSlamantic dataset. Notably, this architecture demonstrates superior performance across all classes in each sequence, indicating its robustness in capturing semantic information.
On average, 5 to 10% of dynamic points are successfully removed from the bike sequence, showcasing the effectiveness of the filtering process. However, an unexpected observation arises when examining the impact on SLAM poses. Despite the successful removal of dynamic points, the filtered points exhibit higher mean, maximum, and RMSE absolute pose errors compared to their unfiltered counterparts in the bike sequence. Surprisingly, this discrepancy does not translate into significant differences in the SLAM trajectory between the filtered and non-filtered scenarios.

3D Domain Adaptation
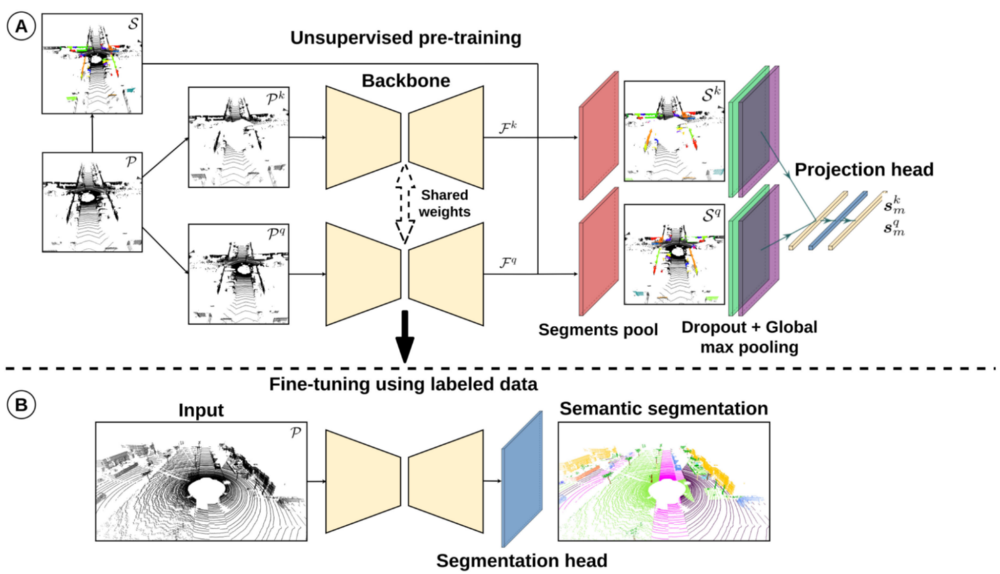
The advantages of ensemble finetuned psuedolabels approach in this context are noteworthy. Firstly, it contributes to improved generalization, mitigating overfitting and enhancing the model’s ability to generalize to unseen data. Secondly, the ensemble exhibits increased robustness, displaying less sensitivity to noise in the training data and outliers. Lastly, the ensemble’s overall performance surpasses that of individual models.

Conclusion
This thesis aimed to improve 3D semantic segmentation performance on the target domain, focusing on the SemanticKITTI Dataset. Integration of Polarmix augmentation played a crucial role, notably enhancing model performance for various classes. However, the traffic-sign class showed a negative impact, contrasting with substantial gains observed for small-size objects like bicycles and motorcycles.
Extending the study to the SemanticSlamantic dataset involved direct inference using models trained on SemanticKITTI. Projection-based approaches required parameter tuning, especially for range images, to adapt to the target dataset. Voxel-based methods outperformed, exhibiting robust performance in qualitative analysis. However, cylinder partition approaches, combined with Polarmix augmentation, struggled outside the trained vertical field of view.
Investigating the effect of dynamic points filtering on SLAM performance showed no significant positive or negative impacts on both SemanticKITTI and SemanticSlamantic datasets. Addressing the domain gap between the datasets, resulting from differences in sensor mounting positions and vertical field of view, extensive experiments and analyses were conducted. Results indicated no single architecture performed optimally across all scenarios. Nonetheless, applying contrastive pretraining and fine-tuning with pseudolabels, generated through an ensemble of architectures and fine-tuned using ensemble hard voting, effectively reduced domain gaps and significantly enhanced model performance.
Bibliography
- Milioto, Andres, Ignacio Vizzo, Jens Behley and C. Stachniss. “RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation.” 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2019): 4213-4220.
- Xiao, Aoran, Jiaxing Huang, Dayan Guan, Kaiwen Cui, Shijian Lu, and Ling Shao. "Polarmix: A general data augmentation technique for lidar point clouds." Advances in Neural Information Processing Systems 35 (2022): 11035-11048.
- Behley, Jens, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. "Semantickitti: A dataset for semantic scene understanding of lidar sequences." In Proceedings of the IEEE/CVF international conference on computer vision, pp. 9297-9307. 2019.
- Zhao, Yiming, Lin Bai, and Xinming Huang. "Fidnet: Lidar point cloud semantic segmentation with fully interpolation decoding." In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 4453-4458. IEEE, 2021.
- Cheng, Hui–Xian, Xian–Feng Han, and Guo–Qiang Xiao. "Cenet: Toward concise and efficient lidar semantic segmentation for autonomous driving." In 2022 IEEE International Conference on Multimedia and Expo (ICME), pp. 01-06. IEEE, 2022.
- Ding, Ben. "LENet: Lightweight And Efficient LiDAR Semantic Segmentation Using Multi-Scale Convolution Attention." arXiv preprint arXiv:2301.04275 (2023).
- Zhou, Hui, Xinge Zhu, Xiao Song, Yuexin Ma, Zhe Wang, Hongsheng Li, and Dahua Lin. "Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation." arXiv preprint arXiv:2008.01550 (2020).
- Choy, Christopher, JunYoung Gwak, and Silvio Savarese. "4d spatio-temporal convnets: Minkowski convolutional neural networks." In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3075-3084. 2019.
- Tang, Haotian, Zhijian Liu, Shengyu Zhao, Yujun Lin, Ji Lin, Hanrui Wang, and Song Han. "Searching efficient 3d architectures with sparse point-voxel convolution." In European conference on computer vision, pp. 685-702. Cham: Springer International Publishing, 2020.
- Nunes, R. Marcuzzi, X. Chen, J. Behley and C. Stachniss, "SegContrast: 3D Point Cloud Feature Representation Learning Through Self-Supervised Segment Discrimination," in IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2116-2123, April 2022, doi: 10.1109/LRA.2022.3142440.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter