Vincent Reß
Analysis and implementation of rotation-equivariant neural network architectures for feature extraction
Duration: 6 months
Completition: July 2023
Supervisor: Dr.-Ing. Markus Brändle (MBDA Deutschland GmbH)
Examiner: apl. Prof. Dr.-Ing. Norbert Haala
Introduction
Due to the sharing of weights within ‘receptive fields’ Convolutional Neural Networks (CNN) are equivariant to translations of the image content. This is an important characteristic for applications in the field of pattern recognition or feature extraction, as it allows objects or interest points to be detected and matched regardless of their position in the image. However, since CNNs do not have a ‘natural’ equivariance to rotations, many applications require a predefined orientation of the images for a reliable extraction and description of keypoints or other features. Although some training methods and network architectures have been developed and evaluated for tasks like pattern recognition and image segmentation, there is a lack of comparable assessments for deep architectures in the field of feature extraction.
With the aim of extracting rotationally equivariant features, various methods that achieved promising results in the field of pattern recognition were implemented and analysed in this thesis to increase the tolerance towards rotated input data. Therefore, adoptions of the training pipeline as well as changes in the network architecture were examined. The D2-Net [1] architecture, which gains competitive performance especially in regard to changes of the image domain, was used as reference.
Methodology
The adaptations to the training pipeline were implemented through a rotation-augmented training. For this purpose, the training data of the MegaDepth [2] dataset was rotated by angles of ±180° and cropped before the hand-over to the encoder of the D2-Net.
To achieve an equivariant network architecture, the layers of the D2-Net where substituted by layers of the Harmonic Network (H-Net) [3] and Rotation Equivariant Vector Field Network (RotEqNet) [4]. Through parameter studies and measurements of the mean feature map distance of the last layer of the encoder, the parameter combination with the best equivariance properties was selected. To compensate the lower number of training weights of the H-Net caused by the restriction to circular harmonics, the number of input and output channels per layer were doubled in comparison to the original D2-Net architecture. As a compromise between the number of operations and the proportion of masked weights, the size of the filter kernels of the RotEqNet-Layer was increased to 5x5 pixels. To exclude the possibility that an equivariant behaviour was trained, the training of the adopted architectures was carried out without an augmentation of the input data.
The equivariance of the trained models was evaluated on rotated images of the HPatches dataset [5]. The extracted keypoints and descriptors were matched with a non-rotated reference image and the mean matching accuracy (MMA) with respect to the angle of rotation was calculated. The evaluation of the general extraction performance was based on the HPatches benchmark. In addition to the analysis on the HPatches dataset, the relative mean inference times in comparison to the reference architecture were determined.
Results
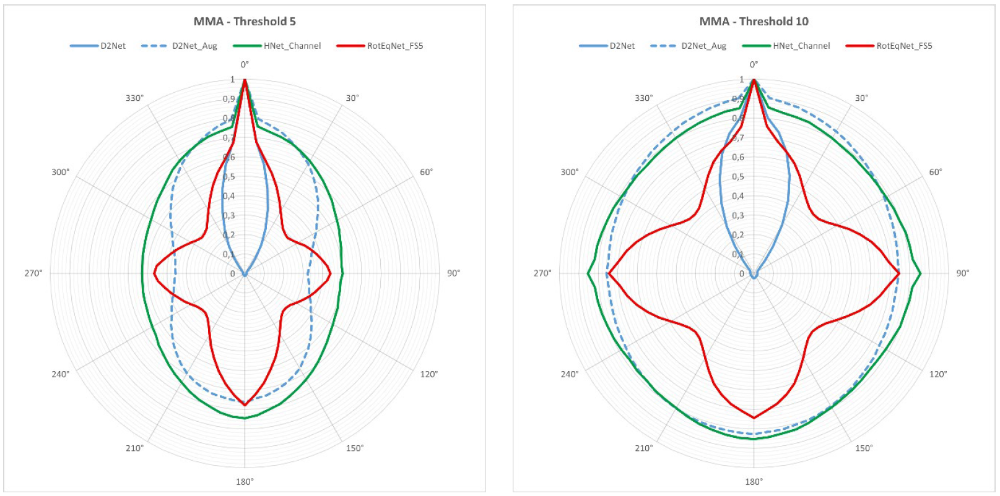
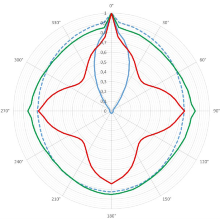
Figure 1 demonstrates the impact of the adapted network and training structure on the equivariance behaviour of the D2-Net architecture. The graph clearly illustrates that all approaches show a remarkable improvement in handling rotated input data. Among them, the H-Net layer adaptation achieves the best results, exhibiting a matching accuracy that remains nearly consistent regardless of the angle of rotation.
The augmented trained D2-Net model tends to form local minima especially at low thresholds in the angular ranges of 90° and 270° degrees. The introduction of RotEqNet-Layer leads to local maxima for the angles of 90°, 180° and 270°, with the determined MMA dropping by up to 30 percentage points in the angular ranges in between.
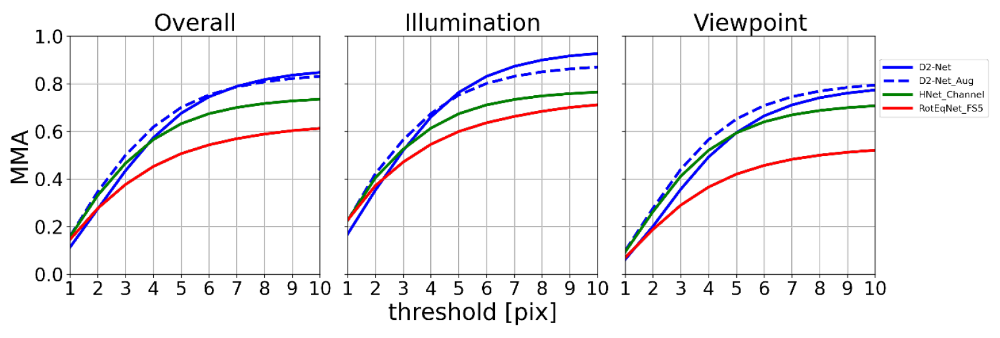
The best overall result (Overall) on the HPatches benchmark is achieved by the augmented trained D2-Net architecture (D2Net_Aug) (cf. figure 2). Especially in separate consideration of perspective transformations (Viewpoint), the results of the reference architecture are surpassed. By using equivariant H-Net layers, comparable MMAs are achieved up to a threshold of 4pix to the reference architecture. However, these drop significantly for larger thresholds below those of the D2-Net. By far the lowest overall performance of all types of adaptation considered is obtained by the introduction of RotEqNet layers.

The measured values shown in table 1 illustrate that the modification of the D2-Net architecture with H-Net layers raises inference times by 280%, while the adaptation with RotEqNet layers results in 3000% increased inference times.
Discussion and Conclusion
The surprisingly poor overall performance of the RotEqNet layers on the HPatches benchmark can be explained by the masking and interpolation method used by the authors for the rotation of the filter kernels. The resulting propotion of non-masked weights depends on the filter size defined in the design and, for the small filter sizes used, leads to strongly limited development potential of the filter weights. The high inference times are caused by additional convolution operations for the rotated filter kernels.
The results of adaptation by the H-Net layer are in line with expectations from previous publications, both in terms of equivariance behaviour and general feature extraction properties. The difference in overall performance on the HPatches dataset can be explained by the "kernel constraint" and the associated limited development possibilities of the filter kernels.
Contrary to the original expectation the augmented network outperforms the reference network by a few percentage points, especially for high accuracy requirements ( ). This suggests a high percentage of unused weights in the reference architecture that are ‘activated’ by the augmentation, thus preserving the range of different filter kernels specialized for the task. However, well-founded statements in this regard can only be made on the basis of further analyses of the filter structures.
In summary, the equivariance behaviour of the reference architecture could be significantly improved on the basis of all types of adaptation presented. Considering the evaluation methods presented, the best overall results were achieved by augmented training. The introduction of equivariant layer types tended to lead to significantly increased inference times and reduced performance on the HPatches benchmark. However, especially with small training data sets, adapted layers can have advantages over augmented training.
References (Selection)
[1] M. Dusmanu et al., “D2-Net: A Trainable CNN for Joint Detection and Description of Local Features,” May. 2019. [Online]. Available: https://arxiv.org/pdf/1905.03561
[2] Z. Li and N. Snavely, “MegaDepth: Learning Single-View Depth Prediction from Internet Photos,” in Computer Vision and Pattern Recognition (CVPR), 2018.
[3] D. E. Worrall, S. J. Garbin, D. Turmukhambetov, and G. J. Brostow, “Harmonic Networks: Deep Translation and Rotation Equivariance,” Dec. 2016. [Online]. Available: https://arxiv.org/pdf/1612.04642
[4] D. Marcos, M. Volpi, N. Komodakis, and D. Tuia, “Rotation Equivariant Vector Field Networks,” 2016. [Online]. Available: https://arxiv.org/pdf/1612.09346
[5] V. Balntas, K. Lenc, A. Vedaldi, and K. Mikolajczyk, “HPatches: A benchmark and evaluation of handcrafted and learned local descriptors,” Apr. 2017. [Online]. Available: http://arxiv.org/pdf/1704.05939v1
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter