Johannes Ernst
Combination of Weakly Supervised Learning and Active Learning for 3D Point Cloud Classification with Minimum Labeling Effort
Duration: 6 months
Completition: November 2022
Supervisor: MSc Stefan Schmohl
Supervisor & Examiner: Prof. Dr.-Ing. Norbert Haala
Introduction and Motivation
Over the last decade, deep learning has become a well-established method for interpreting and classifying 3D point cloud data. Usually, large amounts of annotated training data are needed in order to create meaningful models that can solve such complex tasks. Manually annotating point clouds means to assign a semantic label to the whole dataset point by point. This process is extremely time-consuming considering that the size of point clouds oftentimes exceeds multiple million points, especially in the case of airborne laser scanning. Recently, various approaches have been researched towards tackling the training data creation problem. The goal of this thesis is to combine weakly supervised learning and active learning in a single framework to effectively minimize the labeling effort in the context of 3D point cloud classification. Weakly supervised learning uses coarse labels which are significantly easier to obtain. In this work, weak labels in form of scene-level annotations are used as training data instead of pointwise semantic information. The idea with active learning is to further reduce the amount of training data by choosing the most informative samples for the network learning process.
Theoretical Foundation
KPConv
In 2019 [Thomas et al., 2019] presented the so-called Kernel Point Convolution (KPConv) framework that incorporates the idea of point convolution, originally adapted from the 2D image pixel processing approach, for 3D convolutional neural networks (CNNs). The network is used as state-of-the-art reference when it comes to recognition and interpretation of point clouds. In this setting, points are usually not given in a fixed grid but rather randomly spaced. Therefore, a neighborhood relation has to be defined. KPConv uses radius neighborhood in form of a spherical kernel with several so-called kernel points inside. The convolution is performed for all input points inside the kernel with respect to their corresponding distance to the kernel points. The responses of all kernel points are added up to create an output point. This process is repeated for all kernel positions to perform the point convolution on the whole point cloud. In this work, the KPConv implementation is used as a backbone network.
Weak Supervision
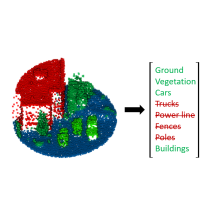
The motivation with weak supervision learning is to train deep learning models without the need for massive sets of hand-labeled training data. In this sense, it is opposed to full supervision learning. The idea is to obtain a weakly labeled training set by leveraging high-level, noisy or heuristically generated data to considerably reduce the labeling effort. Ultimately, the goal is to achieve comparable results when put into contrast to a fully supervised network [Ratner et al., 2019]. In the context of 3D point cloud semantic segmentation, weak labels can be scene-level labels (Figure 1).

Scene-level labels (also referred to as weak region labels) are significantly cheaper to produce when compared to pointwise annotations. Here, a human annotator would receive a scene taken from a 3D point cloud model and be tasked to select all occurring classes from a dictionary of possible labels.
Active Learning
Another approach to overcome the problem of labeled 3D training data is active learning (AL). The main motivation is to train better performing networks by letting the so-called active learner (in this case the CNN) decide which training data to choose. Usually, this decision is based on the goal of drawing the most information out of the training data. For example, if the results of a network prove to be confident for a specific class but less confident for others, it makes sense to choose more training data representing the latter classes than vice versa. Consequently, AL can be useful for cases where great amounts of unlabeled data is available, but, due to limited labeling budget or because of a predefined threshold, only a small amount of labeled data will be created. In this work, an uncertainty-based sampling approach is used to select the training samples. It revolves around the assumption that training examples, where the network gives the least confident predictions, inherit the most information to improve the model [Settles, 2009].
Methodology and Implementation
Using KPConv as a backbone, [Wei et al., 2020] adapted the network to use weak labels instead of pointwise annotations, by introducing multi-path region mining (MPRM). The core idea is to use scene-level labels in form of binary class occurrence vectors as described in Figure 1. [Lin et al., 2022] proposed a refined version of the MPRM approach (called WeakALS) by additionally considering an overlap region loss, that leverages information from overlapping weak region labels. In combination with some other enhancements, this adaptation increased the overall accuracy by several percentage points on all tested datasets. Based on the implementation of [Lin et al., 2022] the network is reworked and further enhanced with an active learning pipeline. Figure 2 shows the developed Weakly Supervised Active Learning network (WeaSAL):
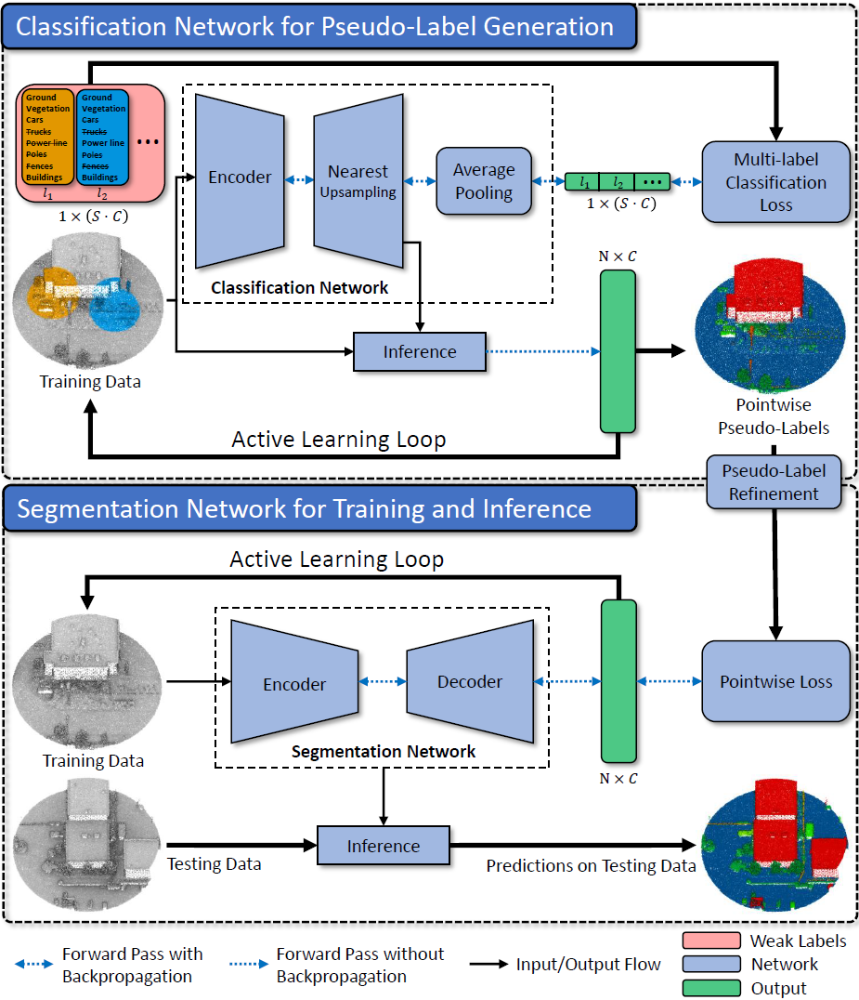
The approach encompasses two cooperating networks, referred to as classification network and segmentation network. Each piece of training data with N points is divided into S subspheres (or subclouds) which are assigned weak region labels according to C classes (compare orange and blue subsphere in Figure 2 with corresponding labels l1 and l2). The points and features of the training data are fed to the classification network’s encoder which consists of several convolutional layers. The last convolutional layer of the encoder gives class prediction probabilities for the data in embedded space. Nearest upsampling is used to infer the respective class labels for all points of the input cloud. Since the indices of all points inside each subcloud are known, average pooling can be used to create a single weak region label prediction vector for each subsphere, that holds the probabilities for each class. In combination with the ground-truth weak region labels, this output can be used to calculate the multi-label classification loss for the network training. After model convergence, so-called pointwise pseudo-labels can be inferred. The corresponding prediction probability is used for AL and to determine the most informative subclouds for the next training iteration. The pseudo-labels are refined with help of the ground-truth weak region labels and then used to train the segmentation network. Here, a similar, but deeper layered encoder is used to first downsample the data. In contrast to the classification network, a decoder brings the data back to its original dimension. The outputs of the decoder are classwise probabilities for each point in the input cloud. With the refined pseudo-labels, a pointwise loss is calculated for the segmentation network training. Another AL loop is integrated that selects the least confident class predictions of the cloud. In the next learning iteration, the corresponding pointwise pseudo-labels can be replaced with ground-truth point labels to further improve the network performance. The final model is used for inference on a testing dataset.
The project code is openly available on GitHub: https://github.com/JohannesErnst/WeaSAL
Analysis and Experiments
To test the WeaSAL network and to evaluate the performance, two distinct benchmark datasets are used, namely the ISPRS Vaihingen 3D (V3D) dataset [Niemeyer et al., 2014] and the Dayton Annotated LiDAR Earth Scan (DALES) dataset [Varney et al., 2020]. Various configurations are tested both without and with AL. The most relevant experiments are showcased in Table 1 (for the V3D dataset) and Table 2 (for the DALES dataset).
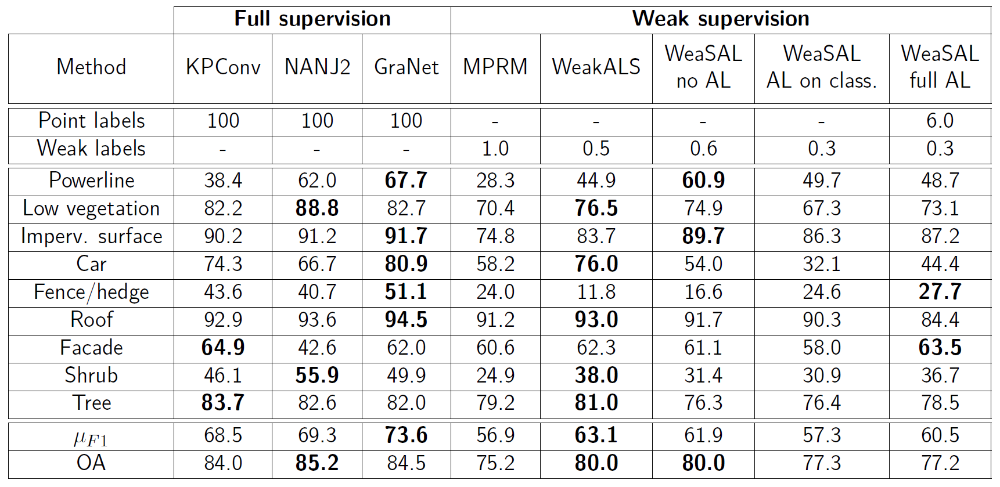
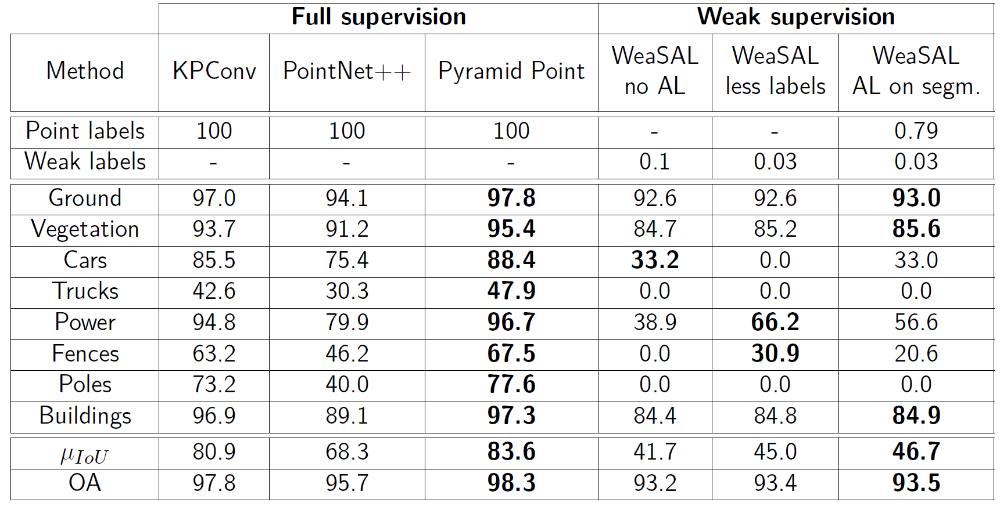
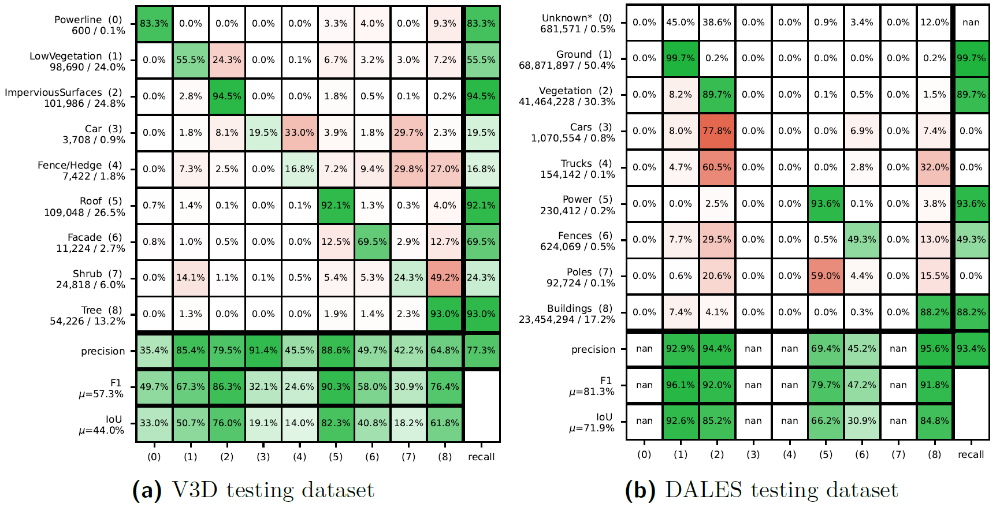
The goal of combining weakly supervised learning and active learning to effectively minimize the labeling effort is reached: With 2400 weak region labels (i.e., 0.3 % of all points) an accuracy of 77.3 % OA and 57.3 % average F1 on the ISPRS Vaihingen 3D dataset is achieved (Figure 3a). Respectively, this is 6.7 and 11.2 percentage points lower than with the fully supervised KPConv network, but with drastically decreased labeling effort. Similarly, the network is trained on the DALES dataset using 98,000 weak region labels (i.e., 0.03 % of all points). With this configuration 93.4 % OA, which is only 4.4 percentage points lower when compared to full supervision, is reached (Figure 3b). The average IoU is considerably lower with 45.0 %. However, this is mainly due to uncommon classes (1.0 % of all points, when combining “cars”, “trucks” and “poles”) which the network fails to predict when only using this very small amount of weak region labels as training data. In Figure 3b, the blank classes are not included in the evaluation scores which leads to a higher average F1 and IoU.
Conclusion
The results showed that weak scene-level labels can be efficiently used to minimize the labeled data. However, a loss in prediction performance was notable for rare classes and small structures. Another outcome was that active learning proves to be a viable method when trying to minimize the weak labels further and selecting the most informative ones. Still, initially picking weak labels equally across all classes was comparably as effective. Especially for uncommon classes, adding additional ground-truth pointwise labels to the network helped to further improve the performance. For this, however, a significant amount of points was needed.
References (selection)
| [Goodfellow et al., 2016] | Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep Learning. MIT Press. url: http://www.deeplearningbook.org. |
| [Lin et al., 2022] | Lin, Y., Vosselman, G., and Yang, M. Y. (2022). Weakly supervised semantic segmentation of airborne laser scanning point clouds. In: ISPRS Journal of Photogrammetry and Remote Sensing 187, pp. 79–100. doi: https://doi.org/10.1016/j.isprsjprs.2022.03.001. |
| [Niemeyer et al., 2014] | Niemeyer, J., Rottensteiner, F., and Soergel, U. (2014). Contextual classification of lidar data and building object detection in urban areas. In: ISPRS Journal of Photogrammetry and Remote Sensing 87, pp. 152–165. doi: https://doi.org/10.1016/j.isprsjprs.2013.11.001. |
| [Ratner et al., 2019] | Ratner, A., Varma, P., Hancock, B., and Ré, C. (2019). Weak Supervision: A New Programming Paradigm for Machine Learning. url: http://ai.stanford.edu/blog/weak-supervision/. |
| [Settles, 2009] |
Settles, B. (2009). Active Learning Literature Survey. Computer Sciences Technical Report 1648. url: |
| [Thomas et al., 2019] | Thomas, H., Qi, C. R., Deschaud, J.-E., Marcotegui, B., Goulette, F., and Guibas, L. J. (2019). KPConv: Flexible and Deformable Convolution for Point Clouds. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 6410–6419. doi: https://doi.org/10.1109/ICCV.2019.00651. |
| [Varney et al., 2020] |
Varney, N., Asari, V. K., and Graehling, Q. (2020). DALES: A Large-scale Aerial LiDAR Data Set for Semantic Segmentation. In: CoRR. doi: https://doi.org/10.48550/ARXIV.2004.11985. |
| [Wei et al., 2020] |
Wei, J., Lin, G., Yap, K.-H., Hung, T.-Y., and Xie, L. (2020). Multi-Path Region Mining For Weakly Supervised 3D Semantic Segmentation on Point Clouds. In: CoRR. doi: |
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter