Zhuo Zeng
Learned Obstacle Representation from Camera Views for Mobile Robots
Duration: 7 months
Completition: August 2022
Supervisor: Dr.-Ing. Gerhard Kurz, M. Sc. Matthias Holoch (both Robert Bosch GmbH)
Examiner: Prof. Dr.-Ing. Norbert Haala
Introduction
Sparse visual SLAM (simultaneous localization and mapping) systems with less processing power and memory consumption have become increasingly appealing for mobile robots. However, these sparse maps for localization task cannot be used for other tasks such as navigation or scene understanding. Therefore, sparse SLAM systems can be combined with learning-based methods to retrieve a dense depth, i.e., we can utilize a deep learning model for dense depth estimation from every single view. Nevertheless, the neural network inherently tends to over-fit the training scenes resulting in a very inconsistent map and more importantly, it still requires a dense update at each pixel if further information from other perspectives is fused.
In this thesis, we have focused on leveraging a compact depth representation to combine depth information over multiple views and construct a consistent map. It maintains the benefit of computational efficiency in sparse methods while preserving the potential of recovering a dense depth for the whole scene. Moreover, we also explored a more precise initialization for the optimization step by utilizing better deep convolutional priors through pre-training.
Methodology
1. Baseline method
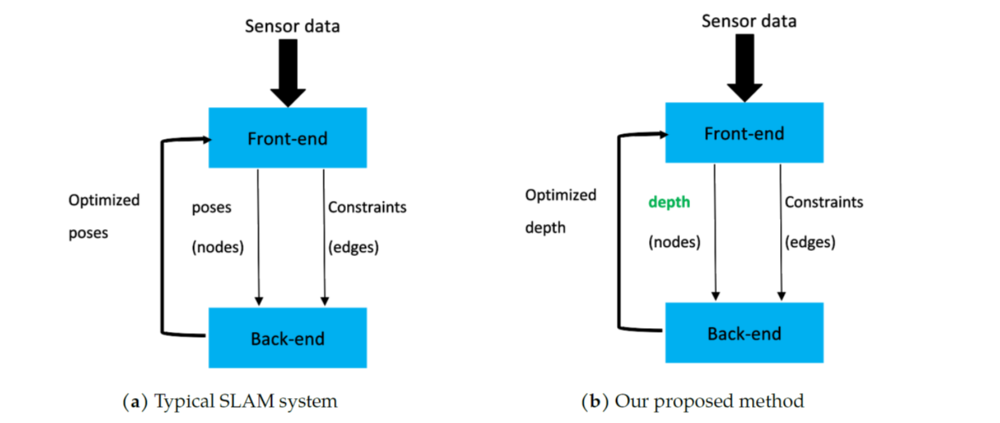
As shown in Fig 1., a typical SLAM system is composed of a frontend and a backend. We replaced the poses with the dense depth value in the frontend to attain a more consistent global map and maintained a non-linear optimization backend as in the typical SLAM.
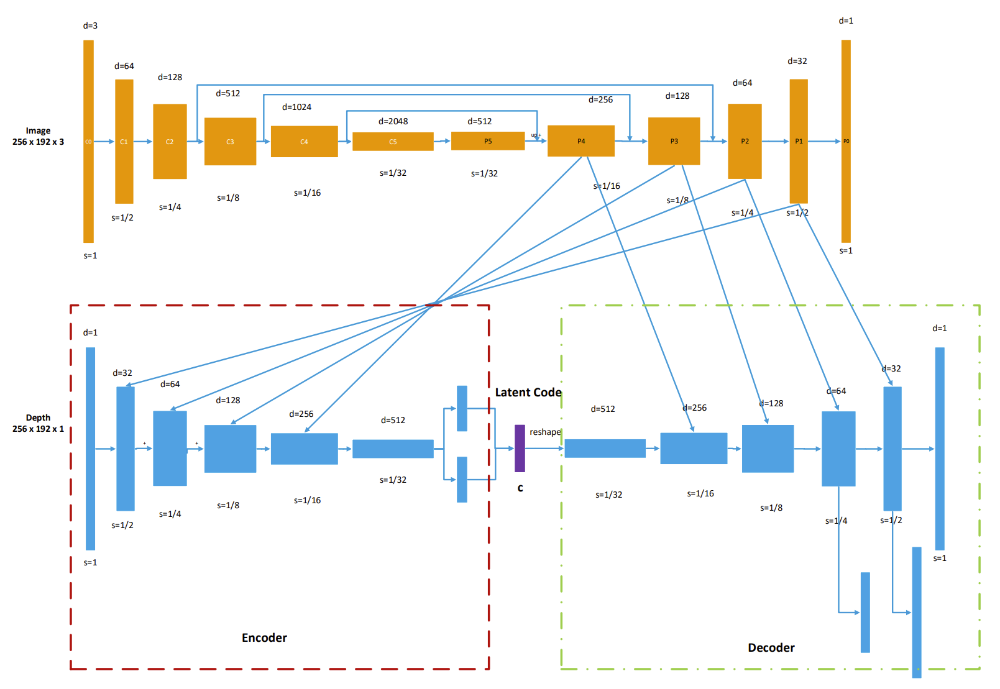
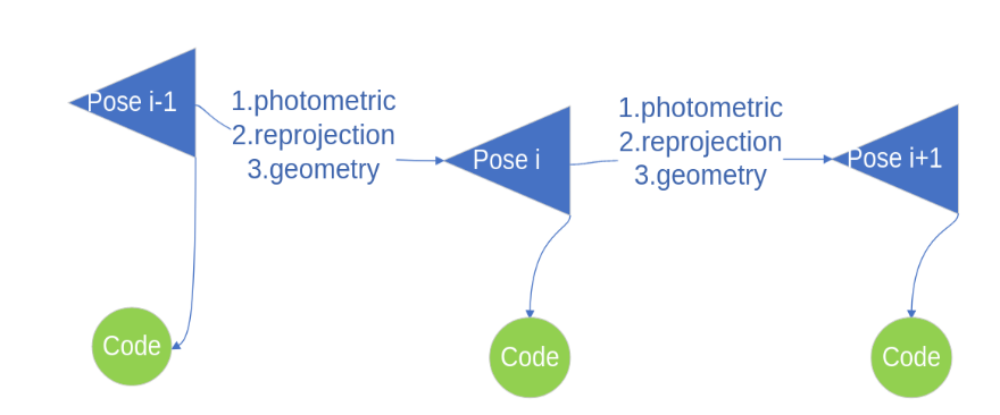
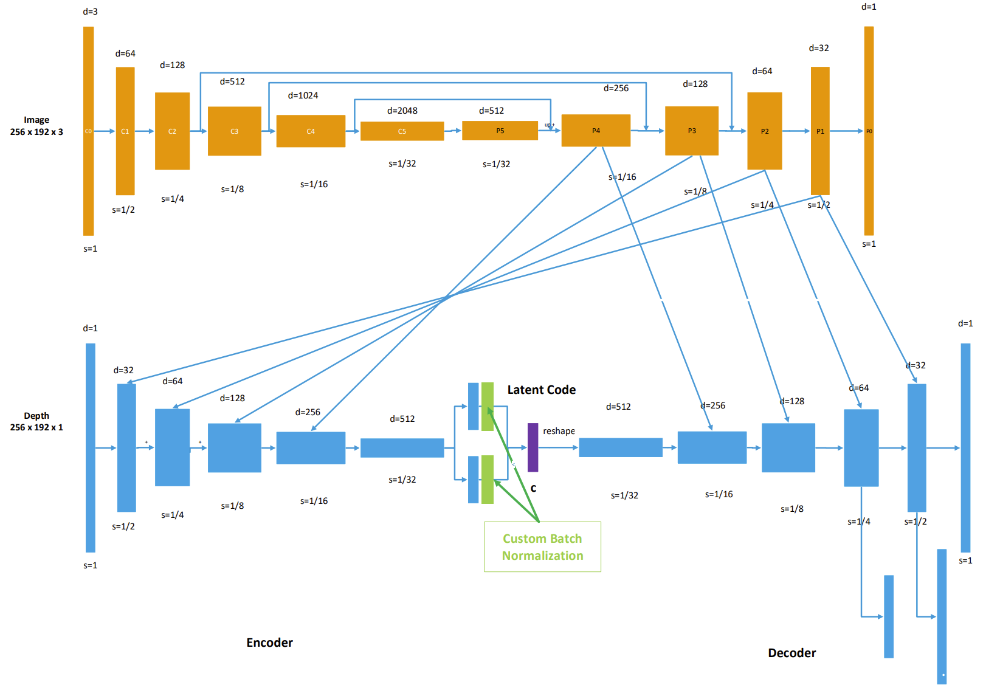
To achieve the goal of sparse and optimizable representation, we adopted same Conditional Variational Auto-encoder (CVAE) as CodeSLAM [1], and DeepFactors [2], as shown in Fig.2. The major advantage is the dense depth can be compressed into a low dimensional latent code (as in purple, in our case d=32 compared with 50,000 dense pixels). With such compact code-representation, we can adopt graph optimization as shown in Fig.3. for more consistent global maps. In pose graph, Landmarks can be fixed and are only regarded as constraints of pose estimation. Inspired by this idea, we can also focus on the latent code and view the poses as constraints.
2. Further Improvement
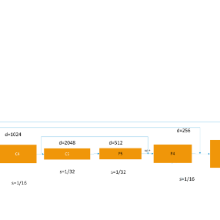
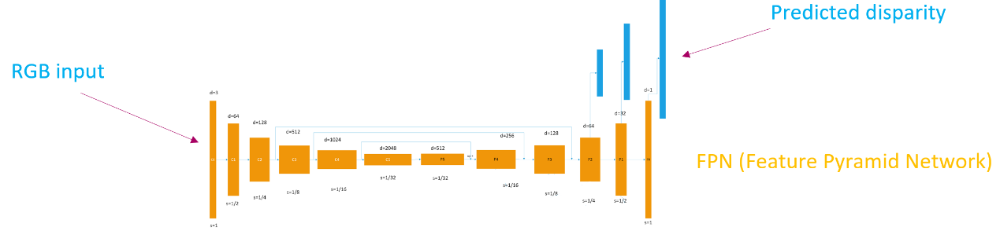
Although the CVAE serves the purpose of optimization perfectly, it sacrifices the expressiveness when compared with standard auto-encoder (e.g., the reconstruction is extremely blur). Therefore, we proposed to utilize the pre-training of Feature Pyramid Network (FPN) for better feature extraction (as shown in Fig. 4) in order to improve the expressiveness of the model. Besides, to avoid the notorious problem of KL-vanishing in the variational auto-encoder, we proposed to add a simple batch normalization module in CVAE as shown in Fig. 5.
Results
1. Qualitative Results
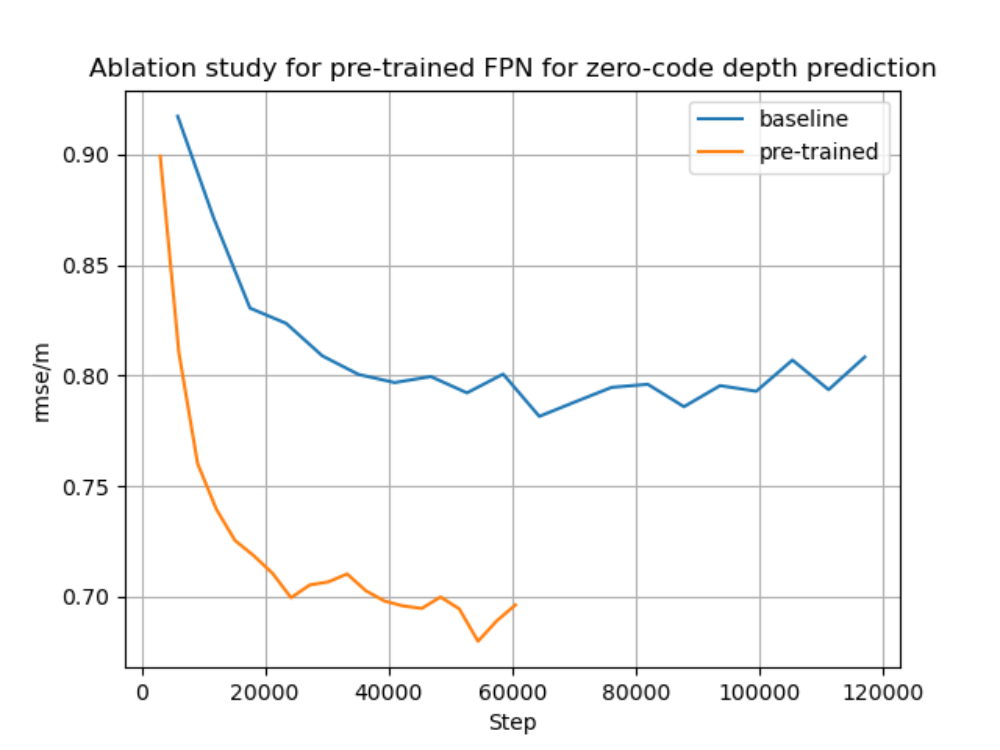
As shown in Figure 6, with a pre-trained FPN the depth prediction is much sharper as FPN alone can provide a more precise depth-related hint for CVAE during pre-training, which successfully reduces the uncertainty of depth prediction around the edges as in the baseline.

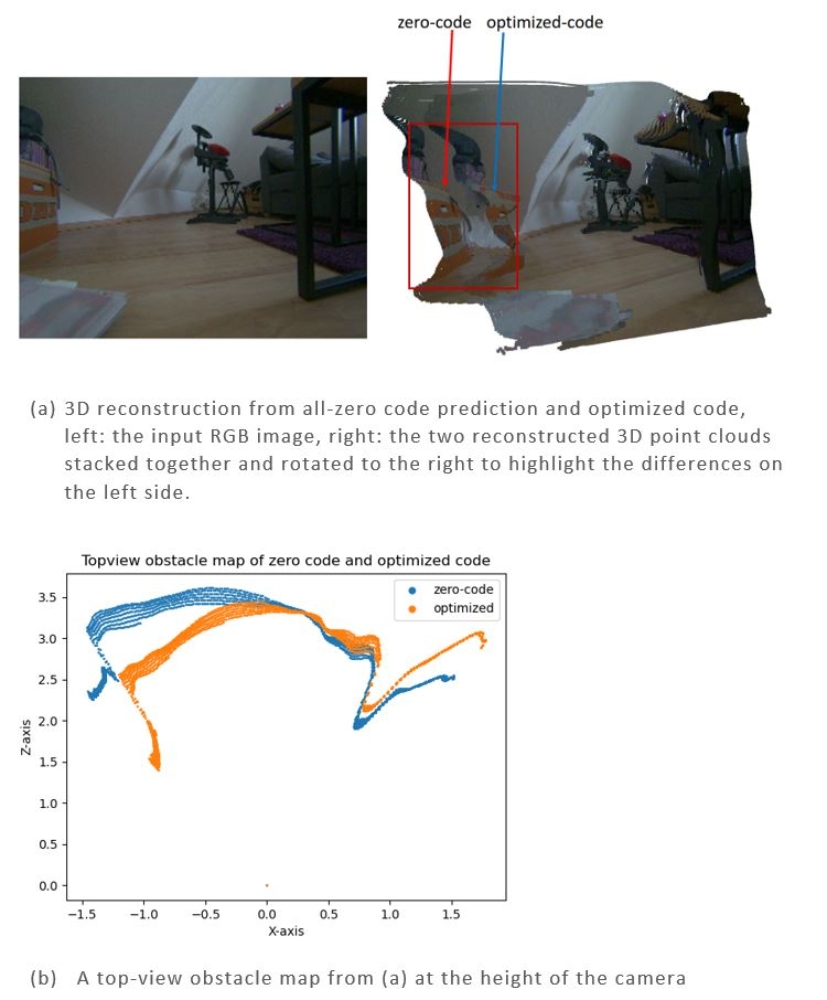
The visualization of 3D reconstruction in Figure 7 (a). highlights another feature of our method: while updating the latent code in a compact manifold, it preserves the capability to influence the dense depth. For a more quantitative illustration of the scene, a top-view obstacle map is created at the camera’s height in Figure 7 (b).
2. Quantitative Results
From table 1, we can easily find out that with a pre-training, all metrics have been improved significantly after applying pre-training, especially the root mean squared error (RMSE) has been improved around 27% for the task of single-view depth estimation.

The data for pre-training comes from a further split of original training data (i.e., 50 % for pre-training task and 50% for reconstruction task as shown in Fig. 8, the pre-trained networks with only the half of the steps), as we aimed at achieving a performance boost without introducing any new data. The data efficiency is desired, as the training data in the real-world use case is generally extremely limited.
Conclusion and Future Work
In this thesis, we have focused on the depth estimation problem from a monocular camera. We examined the feasibility of the compact learned representation for depth with a condition on the RGB image. Moreover, we can provide a more precise initialization for the optimization step by utilizing better deep convolutional priors via pre-training and tackle the problem of KL-vanishing with a batch normalization trick.
For the future work, it can easily generalize to the task of instance or semantic segmentation for an optimizable and consistent global segmentation map. The major modification required is that during the multi-view optimization step, instead of the three losses
(photometric, geometry, re-projection losses) we currently adopted, a new loss should
be used to calculate the distance between two distributions (e.g., KL divergence), as for
segmentation task the soft-max function predicts the possibility for each class instead of a single value as for depth estimation.
Reference
[1] M. Bloesch, J. Czarnowski, R. Clark, S. Leutenegger, and A. J. Davison, “Codeslam — learning a compact, optimizable representation for dense visual slam”, 2018,2560–2568.
[2] J. Czarnowski, T. Laidlow, R. Clark, and A. J. Davison, “Deepfactors: Real-time probabilistic dense monocular slam”, IEEE Robotics and Automation Letters, vol. 5,2, pp. 721–728, Apr. 2020.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter