
Jens Kappler
Durchsatz und Genauigkeit neuronaler Netze für die Objekterkennung im Fahrzeugbereich auf CPU-basierten Systemen
Dauer: 6 Monate
Abgabe: Juli 2022
Betreuer: Dennis Hügle (Vector Informatik GmbH)
Prüfer: Prof. Dr.-Ing. Norbert Haala
Motivation
Die Masterarbeit untersucht das Spannungsfeld aus Durchsatz und Genauigkeit neuronaler Netze für die Objekterkennung im Fahrzeugbereich auf CPU-basierten Systemen. Dafür wird eine repräsentative Auswahl von drei verschiedenen CNN-Architekturen getroffen, die das Potential zur echtzeitfähigen Objekterkennung besitzen. Diese werden mit einem Datensatz aus dem Fahrzeugbereich trainiert. Anschließend werden verschiedene Optimierungsmethoden für neuronale Netze zur Steigerung der Leistung auf CPU-basierten Systemen untersucht. Zuletzt werden die Modelle auf CPU-Architekturen getestet, die spezielle Befehlssätze enthalten, um KI-Anwendungen zu beschleunigen. Das Ergebnis der Arbeit soll Aufschluss darüber geben, für welchen Anwendungsfall es sinnvoll ist, ein Modell zu optimieren.
Architekturen zur Objekterkennung
Da Ziel dieser Arbeit nicht die Entwicklung oder Optimierung bestehender Objekterkennungsarchitekturen ist, werden drei bestehende Architekturen ausgewählt. Dafür werden Kriterien definiert, um eine Auswahl zu erhalten und diese miteinander vergleichen zu können. Kriterien sind beispielweise, dass die Architektur in Benchmarks hohe Genauigkeiten und hohen Durchsatz erreicht, eine Implementierung in PyTorch frei verfügbar ist und das Modell eine Variabilität im Hinblick auf Größe und Anzahl der Parameter des Modells besitzt. Folgende drei Architekturen wurden für diese Arbeit ausgewählt: RetinaNet, YOLOR, EfficientDet. Der Aufbau bestehend aus Backbone, Neck und Head der Architekturen ist in den folgenden Abbildungen zu erkennen.
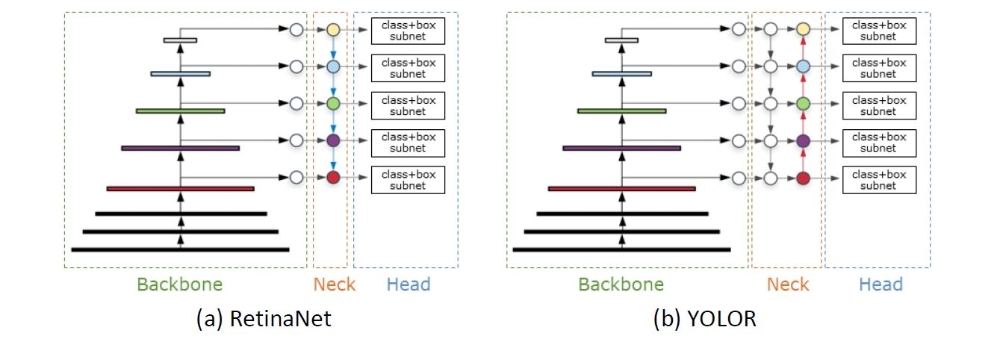
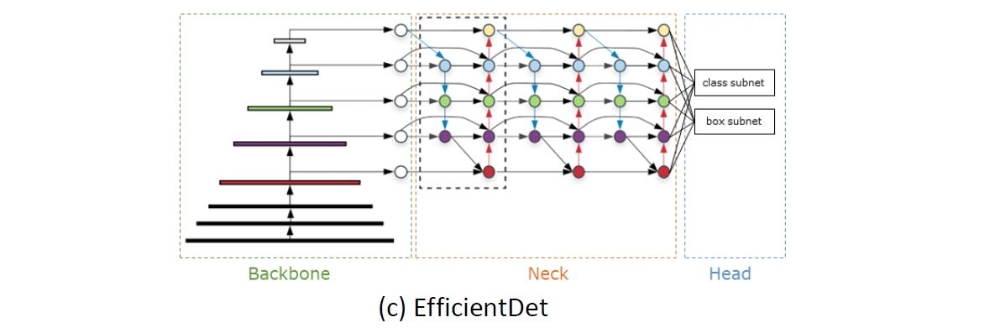
Für das RetinaNet stehen die Backbones ResNet50 und MobileNetV2 zur Verfügung. Das Neck ist durch ein Feature Pyramid Network (FPN) realisiert. You Only Learn one Representation (YOLOR) ist eine Erweiterung des Scaled-YOLOv4 und vereinigt ein explizites und implizites Modell. Das Backbone ist ein CSP-Darkent53 und das Neck ein Path Aggregation Network (PANet). Das Backbone des EfficientDet ist ein EfficientNet und das Neck ein Bi-directional Feature Pyramid Network (BiFPN). Alle Architekturen implementieren den Focal Loss als Loss-Funktion und gehören zu den one-stage Architekturen.
Methodik
Die Modelle werden mit dem Berkeley DeepDrive 100K (BDD100K) Datensatz trainiert. Dieser enthält 100.000 Bilder aus dem Fahrzeugbereich mit zehn Objektklassen. Hierfür wird eine Trainings-Pipeline implementiert, in der die Modelle trainiert und anschließend in das Open Neural Network Exchange (ONNX) Format konvertiert werden. Pro Architektur wird ein Modell mit kleinem und ein Modell mit großem Backbone trainiert. In einer Optimierungs-Pipeline werden die Modelle anschließend mit dem openVINO Model Optimizer optimiert. Bei openVINO handelt es sich um ein Toolkit zur Optimierung des Durchsatzes neuronaler Netze. In einer Benchmark-Pipeline werden die Modelle auf Durchsatz und Genauigkeit getestet. Dazu wird der Validierungsdatensatz des BDD100K verwendet. Zu den untersuchten Optimierungen gehören die Halbierung der Netzwerkeingangsgröße, die Optimierung durch openVINO sowie die Quantisierung der Modelle.
Ergebnisse
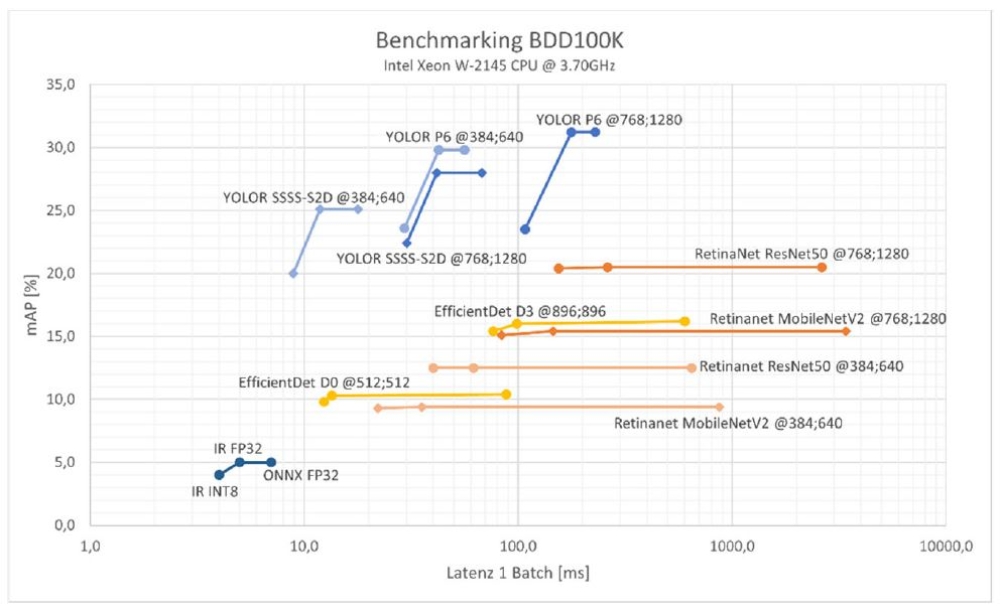
Die folgende Grafik zeigt die Ergebnisse der Benchmark-Pipeline. Die drei Datenpunkte pro Modellkonfiguration stehen für das ONNX Modell (rechts), das optimierte Modell durch openVINO (mitte) und das quantisierte Modell (links). Das YOLOR erzielt die höchste Genauigkeit, verliert durch die Quantisierung jedoch auch an Genauigkeit. RetinaNet und EfficientDet profitieren am meisten durch die Optmierung und Quantisierung mit openVINO. Die geringere Netzwerkeingangsgröße hängt immer mit einem Genauigkeitsverlust zusammen.
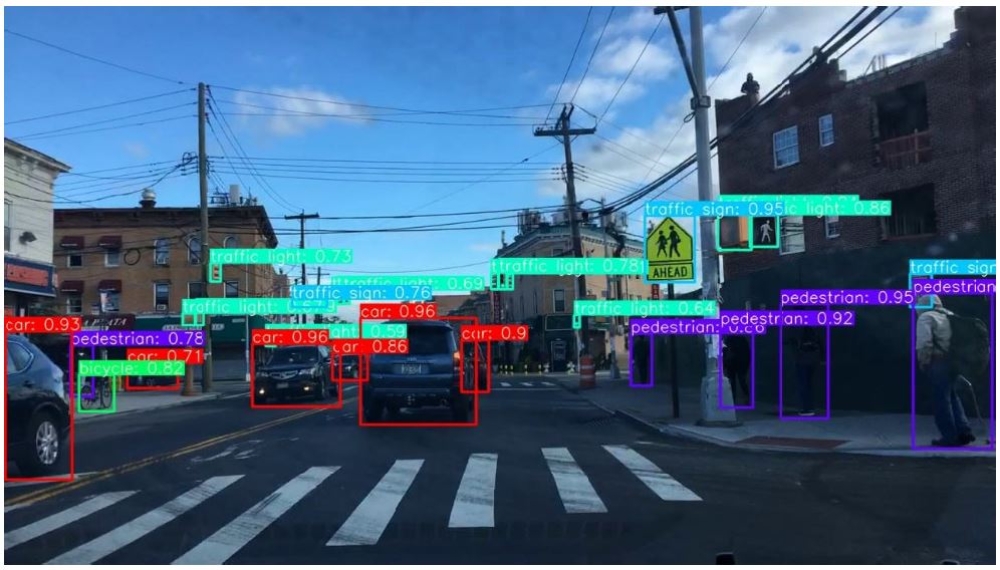
Die nachfolgende Grafik zeigt die erkannten Objekte auf einem Bild des Validierungsdatensatzes des BDD100K. Dafür wurde das YOLOR-P6 (768x1280) verwendet, welches das genauste Modell der Versuche ist. Es zeigt, dass sowhol große Objekte im Vordergrung erkannt werden, als auch kleine Objekte wie Lichtzeichenanlagen und Verkehrsschilder.
Fazit
Es wurden drei one-stage Architekturen trainiert, Optimierungsmöglichkeiten getestet und die Ergebnisse miteinander verglichen. Es hat sich gezeigt, dass die YOLOR Architektur den höchsten Durchsatz und die höchste Genauigkeit erzielt. Die Optimierungen der Modelle wirken sich auf jede der drei Architekturen anders aus und haben unterschiedliche Ergebnisse zur Folge. So profitieren RetinaNet und YOLOR durch Quantisierung von einer Beschleunigung des Durchsatzes, die Genauigkeit nimmt beim YOLOR jedoch ab. Durch verkleinern der Netzwerkeingangsgröße werden beim EfficientDet alle Komponenten der Architektur skaliert. Dies hat einen höheren Durchsatz zur Folge. Allerdings sind die kleinen Netzwerkeingangsgrößen beim EfficientDet unvorteilhaft für das Erkennen kleiner Objekte. ResNet Backbones, oder dem ResNet ähnliche Backbones wie das MobileNetV2 und EfficientNet, eignen sich am besten für die Optimierung durch openVINO. Auserdem erzielen das ResNet50 und MobileNetV2 die größten Beschleunigungen des Durchsatzes durch die Quantisierung. Der beste Kompromiss aus Durchsatz und Genauigkeit in dieser Arbeit ist beim YOLOR zu finden. Das RetinaNet-MobileNetV2 ist für die Quantisierung am besten geeignet. Das Potential zur Leistungssteigerung ist beidiesem Modell am größten.
Literatur (Auswahl)
Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollar, P. (2018). Focal Loss for Dense Object Detection. CoRR, abs/1708.02002. https://arxiv.org/abs/1708.02002
openVINO. (2022). openVINO Documentation. https://docs.openvino.ai/latest/documentation.html
Tan, M., Pang, R., & Le, Q. V. (2019). EfficientDet: Scalable and Efficient Object Detection. CoRR, abs/1911.09070. http://arxiv.org/abs/1911.09070
Wang, C.-Y., Yeh, I.-H., & Liao, H.-Y. M. (2021). You Only Learn One Representation: Unified Network for Multiple Tasks. CoRR, abs/2105.04206. https://arxiv.org/abs/2105.04206
Yu, F., Xian, W., Chen, Y., Liu, F., Liao, M., Madhavan, V., & Darrell, T. (2018). BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling. CoRR, abs/1805.04687. http://arxiv.org/abs/1805.04687
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter