
Lukas Lansche
2D-Modellierung von Weinreben unter Verwendung verschiedener Machine Learning Methoden
Dauer der Arbeit: 6 Monate
Abgabe: Oktober 2020
Supervisor: M.Sc. Stefan Schmohl
Examiner: Prof. Dr.-Ing. Norbert Haala
Motivation und Ziel
Für die Gewährleistung einer effizienten Landwirtschaft, werden einzelne Arbeitsschritte immer öfter automatisiert. Dieser Umschwung ist auch im Weinbau zu erkennen. Derzeit gibt es für die meisten Arbeitsschritte mechanische oder automatische Verfahren. Für den Rebschnitt, welcher zu Beginn eines Jahres erfolgt und eine wichtige Grundlage für den späteren Ertrag darstellt, gibt es lediglich eine Teilmechanisierung. Ziel dieser Arbeit ist es, eine möglichst genaue und effiziente Methode für die automatische Generierung eines 2D-Modells von Weinreben aus Bilddaten zu entwickeln. Daraus berechnet sich ein Schneidroboter ein 3D-Modell, um so die Koordinaten zu definieren, an welchen ein Roboterarm die Reben zurückschneidet. Für die Erstellung des 2D-Modells werden die Bilder in fünf verschiedene Objektklassen (Ast, Stamm, Draht, Pfosten, Hintergrund) pixelweise klassifiziert und die einzelnen Objekte modelliert. Die Hauptaufgabe besteht darin, die Klasse Ast mit Hilfe von Polylinien so zu modellieren, dass die vollständige Baumstruktur der Rebe erfasst und abgebildet wird.
Vorgehensweise
Die Semantische Segmentierung wurde mit Hilfe von Convolutional Neural Networks realisiert. Dazu wurde ein Trainingsdatensatz von 500 Bildern unter Verwendung einer modifizierten Variante des Active Learnings generiert. Die Bilder dazu wurden vor einem homogenen Hintergrund, wie in Abbildung 1a zu sehen, aufgenommen. Für die Bestimmung der besten CNN Konfiguration wurden verschiedene Kombinationen aus Grundarchitektur (Unet, FCN und DeeplabV3+) und Ecoder-Modellen (ResNet50, SE ResNet50, MobileNetV2 und EfficientNet-B0) getestet. Die von den CNN prädizierten Klassifizierungsmasken dienen als Ausgang für die anschließende Modellierung.

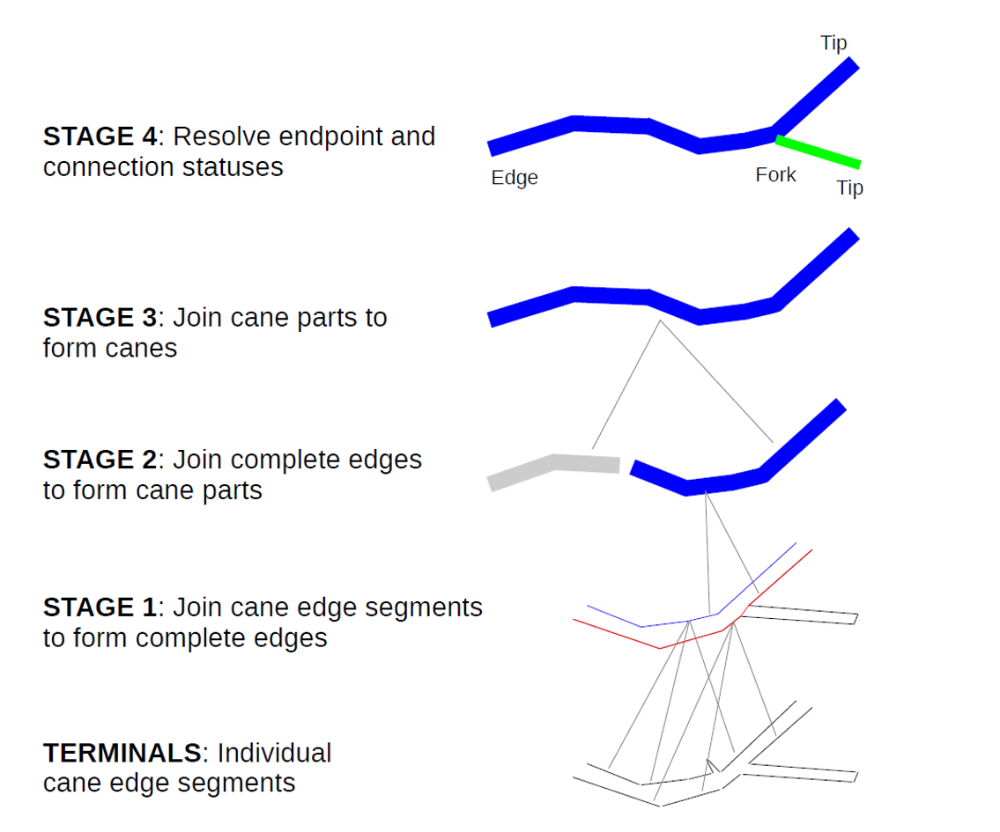
Für die Modellierung der Äste wurden im Zuge dieser Arbeit zwei unterschiedliche Methoden entwickelt. Zum einen wurde eine modifizierte Variante des Bottom-Up-Parsing-Ansatzes von Tom Botterill et. al 2013 verwendet. Das Verfahren ist in verschiedene Schritte aufgeteilt, wie sie in Abbildung 2 zu sehen sind. Die Basis stellen einzelne Kantensegmente dar, welche im Laufe des Verfahrens zu vollständigen Ästen verbunden werden. Die Entscheidungen über das Verbinden der jeweiligen Segmente werden von Support Vector Machines getroffen. Dazu werden drei SVM mit handgelabelten Daten trainiert. Anschließend werden die dadurch gefunden Äste zu einer Baumstruktur aus Polylinien verbunden. Die restlichen Objekte wie der Stamm oder die Drähte werden ebenfalls durch Polylinien oder Polygone beschrieben.
Die zweite Methode versucht mittels Instanz Segmentierung die einzelnen Astinstanzen im Bild zu identifizieren und anschließend zu modellieren. Dazu wurde ein Mask R-CNN mit einem Trainingsdatensatz von 200 handgelabelten Bildern trainiert. Anhand der prädizierten Maske sollen die Polylinien der einzelnen Äste durch eine Skelettierung definiert werden. Die restlichen Arbeitsschritte werden analog zur Bottom-Up-Parsing-Methode durchgeführt.
Ergebnisse und Fazit
Die Ergebnisse der trainierten CNN Kombinationen werden anhand der Accuracy und dem mIoU Score miteinander verglichen. Das beste Resultat liefert das UNet mit dem SE ResNet50 als Backbone, es erreicht eine Accuracy von 0,9826 und einen mIoU Score von 0,9168. Ein Beispielergebnis kann der Abbildung 3 entnommen werden. Allerdings sind die Werte der anderen Netze, mit einem Durchschnittlichen mIoU Score von 0,9, auch als brauchbar einzustufen.

Die modifizierte Variante des Bottom-Up-Parsings liefert für einfach strukturierte Reben ebenfalls gute Resultate, wie in Abbildung 4 zu sehen. Bei Reben mit sehr vielen Ästen treten allerdings häufiger Fehlzuordnungen auf. Teilweise kann der Algorithmus nah beieinander liegende Ruten nicht identifizieren. Das Modell der Rebe ist somit unvollständig und kann nicht für die Weiterverarbeitung verwendet werden.

Der Ansatz mit der Instanz Segmentierung erzielt keine brauchbaren Ergebnisse. 210 Trainingsbilder sind deutlich zu wenig Informationen, um die Äste eindeutig zu identifizieren.
Zusammenfassend lässt sich sagen, dass das Ziel, eine Methode für die Generierung von 2D-Modellen von Weinreben zu erarbeiten nur teilweise erreicht wurde. Die Semantische Segmentierung liefert, dank der Bildaufnahme vor einem homogenen Hintergrund, sehr gute Ergebnisse. Einfach strukturierte Reben lassen sich mit der modifizierten Version der Bottom-Up Parsing-Methode vollständig modellieren. Jedoch werden komplexerer Reben nicht vollständig und teilweise falsch abgebildet. Der Versuch, die einzelnen Reben mit der Instanz Segmentierung zu identifizieren, erbrachte, aufgrund einer zu geringen Anzahl an Trainingsdaten, keine brauchbaren Ergebnisse.
Quelle
| [BGM13] | Botterill, T. ; Green, R. ; Mills, S.: Finding a vine's structure by bottom-up parsing of cane edges. In: 2013 28th International Conference on Image and Vision Computing New Zealand (IVCNZ 2013), 2013, S. 112_117 |
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter