Lina Emilie Budde
Unsicherheitsauswertung von semantischer Segmentierung mittels Neuronaler Netze
Dauer der Arbeit: 6 Monate
Fertigstellung: November 2019
Betreuer: M. Sc. Stefan Schmohl
Prüfer: Prof. Dr.-Ing. Uwe Sörgel
Motivation und Ziel der Arbeit
In der Bildanalyse im Allgemeinen und in der Fernerkundung im Besonderen ist die sogenannte semantische Segmentierung von Bildern, bei der jedem Pixel eine Klasse zugeordnet wird, eine häufige Aufgabe des maschinellen Lernens. Aus Fernerkundungsdaten können so qualitativ hochwertige und aktuelle Landbedeckungskarten erstellt und zum Beispiel für die Land- und Forstwirtschaft, Stadtentwicklung sowie Umweltüberwachung genutzt werden.
Solche automatisch erzeugten Klassifikationen sind grundsätzlich fehlerbehaftet. Zusätzliche Informationen zu ihrer Qualität sind daher wünschenswert.
Die Bedeutung solcher Qualitätsmaße im Bereich der Fernerkundung wird daran deutlich, dass gerade die Landbedeckungskarten eine wichtige Grundlage sowohl politischer als auch wirtschaftlicher Entscheidungen bilden. Indikatoren für mögliche Fehlzuordnungen können außerdem verwendet werden, um effizient manuell nachzubearbeitende Bereiche auszuwählen, sollte eine sehr hohe Klassifikationsgüte erforderlich sein.
Eine Alternative zu den üblichen Genauigkeitsmaßen, welche Referenzdaten als direkte Vergleichsdaten benötigen, stellt die Quantifizierung der Klassifikations-Unsicherheit dar, bei der Unsicherheiten unmittelbar vom Klassifikationsmodell mitgeliefert werden.
In den meisten Deep Learning Modellen fehlen jedoch fundierte Angaben zu auftretenden Unsicherheiten in der semantischen Segmentierung.
Daher ist das Ziel dieser Arbeit die Bestimmung von verschiedenen Unsicherheitsmaßen mittels Monte-Carlo Dropout und die Untersuchung dieser Maße hinsichtlich ihrer Tauglichkeit, unischere Pixel zu identifizieren.
Vorgehensweise für die semantische Segmentierung und Unsicherheitsauswertung
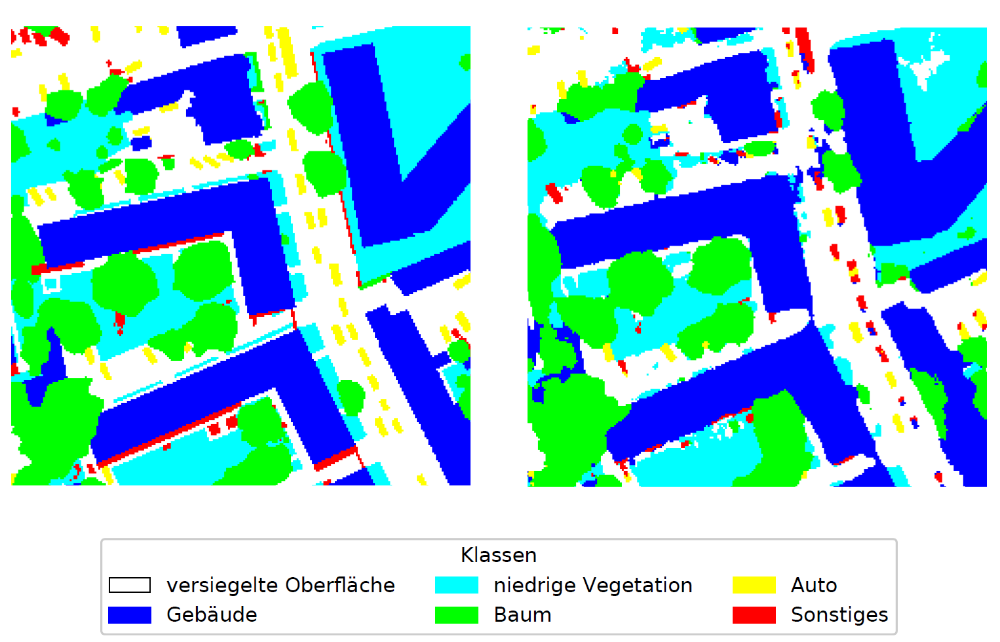
Für die Untersuchungen wird der ISPRS Potsdam 2D Semantic Labeling Benchmark verwendet. Im ersten Schritt wird für die semantischen Segmentierung ein einfaches U-Net mit Bildausschnitten von jeweils Pixel unter der Verwendung der fünf Kanäle RGB, IR & nDSM trainiert.
Statt Dropout bei der Inferenz zu deaktivieren, wird dieses beim Monte-Carlo Dropout genutzt, um bei mehreren Klassifikationsdurchläufen eines Bildes durch das neuronale Netz variierende Pseudo-Wahrscheinlichkeiten pro Pixel und Klasse zu erzeugen. Anschließend wird für die semantische Segmentierung diejenige Klasse prädiziert, die im Mittel die höchsten Pseudo-Wahrscheinlichkeiten hat. Ein Ausschnitt eines solchen Ergebnisses zeigt Abbildung 1.
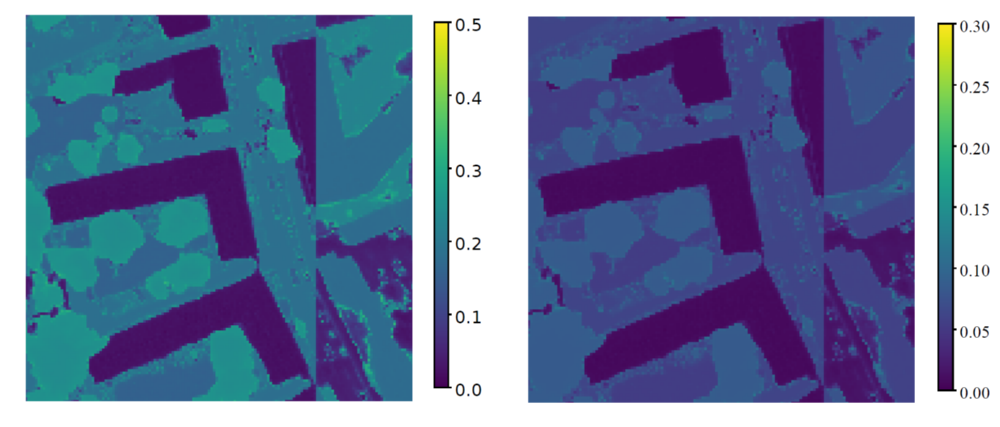
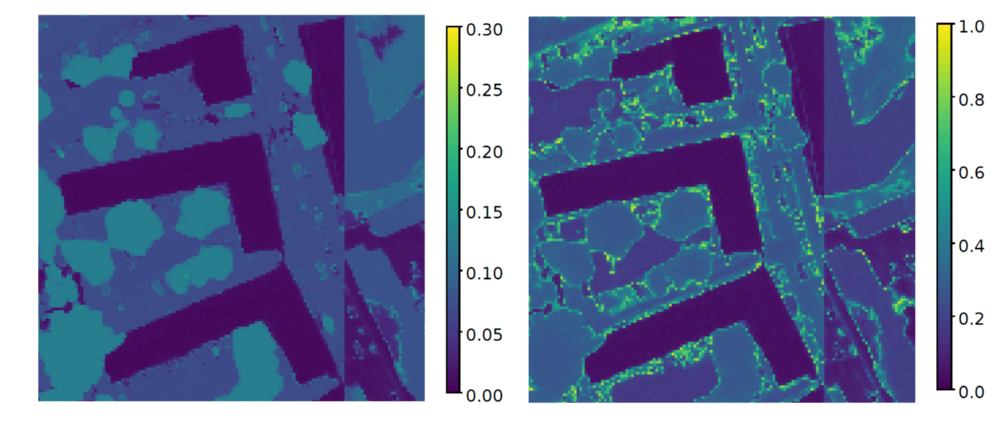
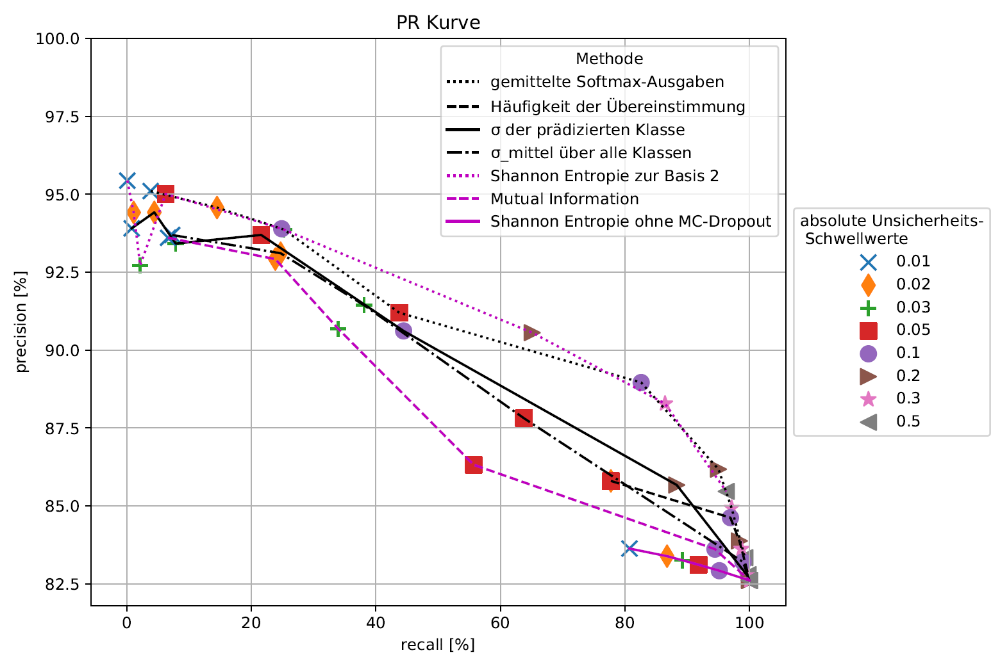
Im nächsten Schritt werden für die Unsicherheitsauswertung aus 20 Monte-Carlo Durchläufen je Bild unter anderem die Standardabweichung, die Mutual Information und die Shannon Entropie als Unsicherheitsmaß pixelweise berechnet (siehe Abbildung 3 und Abbildung 4). Zusätzlich werden noch die gemittelten Pseudo-Wahrscheinlichkeiten und die Häufigkeit der Übereinstimmung der Einzelprädiktionen aus den Monte-Carlo Durchläufen mit der prädizierten Klasse (Abbildung 2) bestimmt. All diese Unsicherheitsmaße werden zum einen optisch über die dazugehörigen Unsicherheitskarten , zum anderen mittels der jeweiligen precision-recall Kurve (Abbildung 5) miteinander verglichen.

Ergebnisse und Fazit
Für die semantische Segmentierung aller Testbilder wird eine Gesamtgenauigkeit von 82,6 % erzielt. Aus der Unsicherheitsauswertung ergibt sich, dass die mittlere Standardabweichung und Mutual Information sich bei der optischen Betrachtung sehr ähnlich sind, aber auch die Standardabweichung der prädizierten Klasse weist viele Gemeinsamkeiten mit diesen beiden Unsicherheitsmaßen auf. Denn bei diesen Maßen scheinen die Unsicherheiten in erster Linie mit der Klassenart zu korrelieren. Im Vergleich dazu sind die Werte der anderen Unsicherheitsmaße, insbesondere der Entropie, entlang der Objektgrenzen am stärksten. In diesen Bereichen sind auch ein großer Teil der Fehlklassifikationen enthalten.
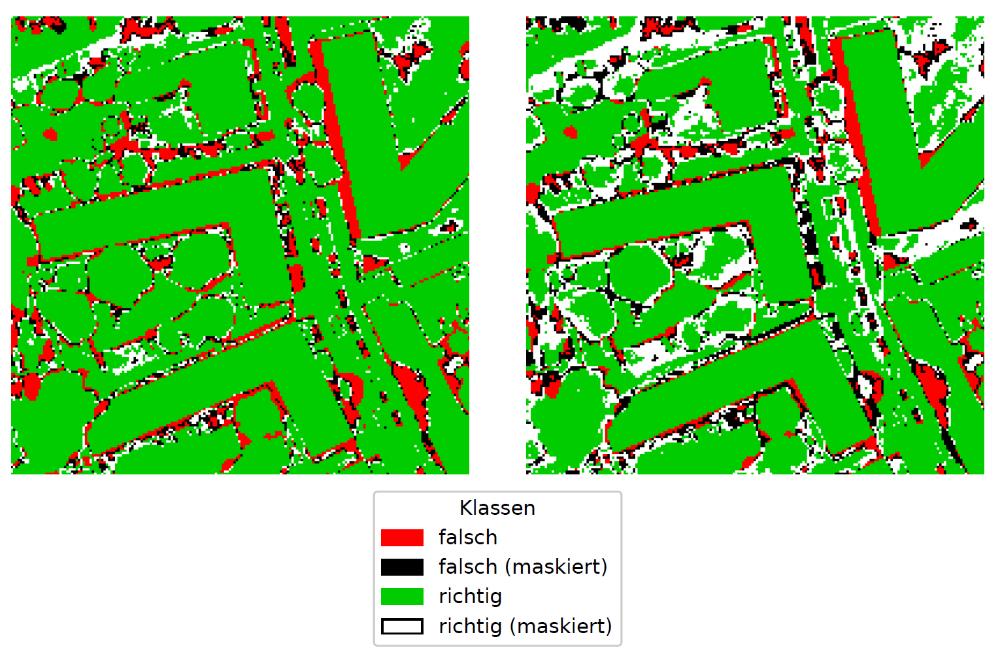
Die precision-recall Kurven aus Abbildung 5 unterstützen den optischen Eindruck, dass die Shannon Entropie das geeignetste Verfahren zur Bestimmung der Unsicherheit ist. Nach dem Herausfiltern von 10 % der Pixel mit den größten Entropiewerten verbessert sich die Gesamtgenauigkeit von 82,6 % auf 86,5 %. Nach der Entfernung von 20 % liegt die Genauigkeit bereits bei 88,2 %. Das Ergebnis solcher Filterungen ist in Abbildung 6 zu sehen. Dabei kann unterschieden werden, ob ein Pixel richtig klassifiziert und gleichzeitig als unsicher identifiziert wurde (weiße Pixel) oder ein Pixel zugleich falsch klassifiziert und als unsicher (schwarze Pixel) eingestuft wurde. In erster Linie werden die Pixel an den Objekträndern herausgefiltert. Jedoch muss in Kauf genommen werden, dass auch die Objektrandpixel, die richtig klassifiziert wurden, aufgrund ihres Entropiewertes aussortiert werden. Je höher die Anforderung an die precision, desto mehr Pixel müssen gegebenenfalls nachbearbeitet werden. Der Schwellwert, nach dem die Pixel als sicher beziehungsweise unsicher kategorisiert werden, kann entsprechend den gewünschten Anforderungen festgelegt werden. Fehlklassifikationen die durch mangelnde Qualität der Eingabedaten entstehen, können dagegen auf diese Weise in der Regel nicht identifiziert werden.