
Zimin Xia
Stereo Reconstruction of Human Faces with Deep Learning
Duration of the Thesis: 6 months
Completion: July 2019
Supervisor: Dr. Jascha Ulrich (Carl Zeiss AG)
Examiner: Prof. Dr.-Ing. Norbert Haala
Motivation
3D reconstruction is the process of capturing the 3D information of shape and appearance of objects. Today, many applications are enabled by 3D reconstruction. For example, the popular Face ID technology equipped by iPhone X and iPad Pro: fast and accurate face recognition using 3D facial map for unlocking the device and doing payment. The 3D reconstruction process can be accomplished by either active or passive methods. This thesis focuses on passive 3D reconstruction methods, specifically, binocular stereo vision: starting with a given pair of rectified facial stereo image, acquiring object’s 3D geometric information based on visual disparity. We put our emphasis on the disparity estimation step, which is one the most important steps within the full binocular stereo vision pipeline.
Thanks to the development of deep learning, the results of many computer vision tasks have been improved dramatically. During the past few years, deep learning-based disparity estimation algorithms have achieved promising on many disparity estimation benchmarks, such as KITTI [1] and Middlebury [2]. Motivated by this, we employ a state-of-the-art disparity estimation convolutional neural network (CNN), called DispNet-CSS [3], for face 3D reconstruction.
Training and Data
Due to the lack of public face data, we generate a face disparity estimation dataset using a public face point cloud dataset from FRGC2.0 [5] and make use of the transfer learning strategy. We first train the network on a large public synthetic dataset, called FlyingThings3D [4], then fine-tune the network on the generated face data, which contains 7646 training sets and 1178 test sets.
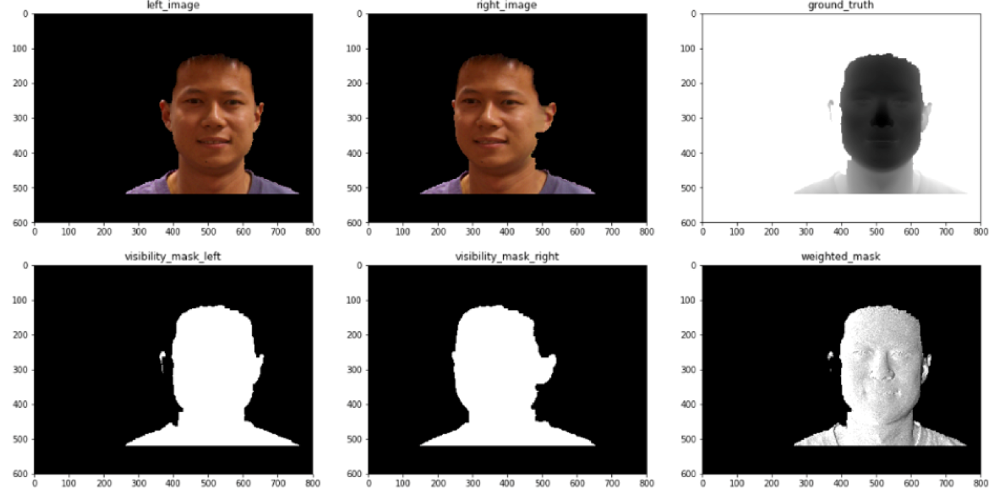
Evaluation
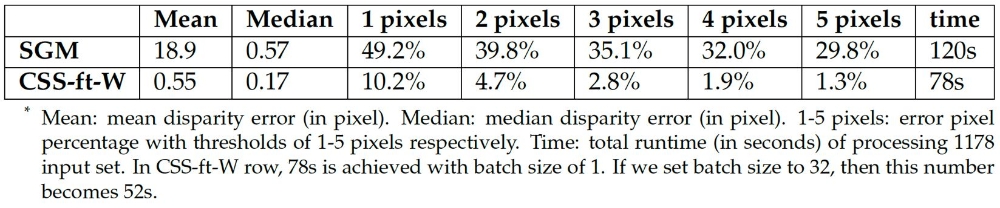
We reproduced the training from [4], and get similar evaluation results on FlyingThings3D [4] proposed in literature. On the face test set, we evaluate the network and compare the performance of the network to a benchmark algorithm, Semi-Global Matching (SGM). As shown in table, our network surpasses the SGM in both accuracy and running time on the face test set.
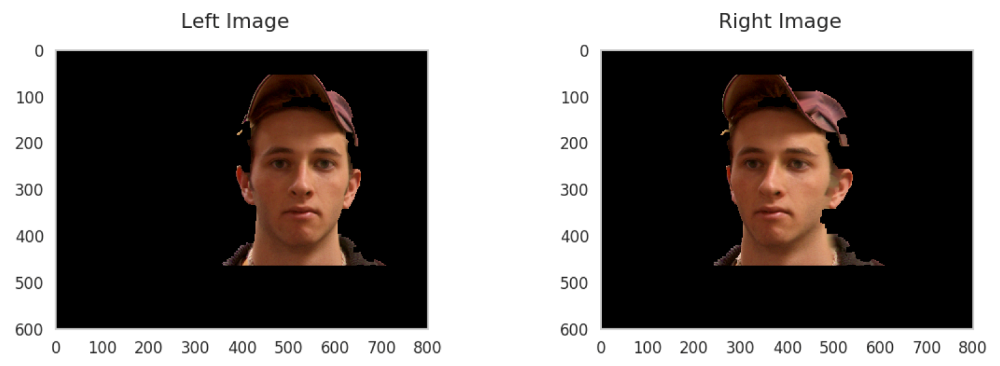
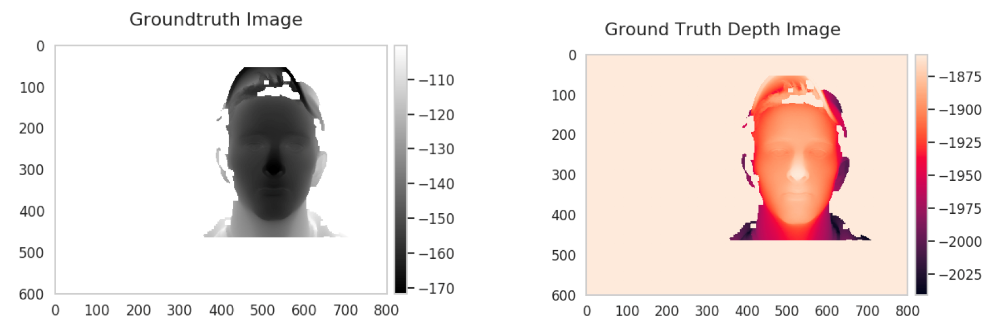
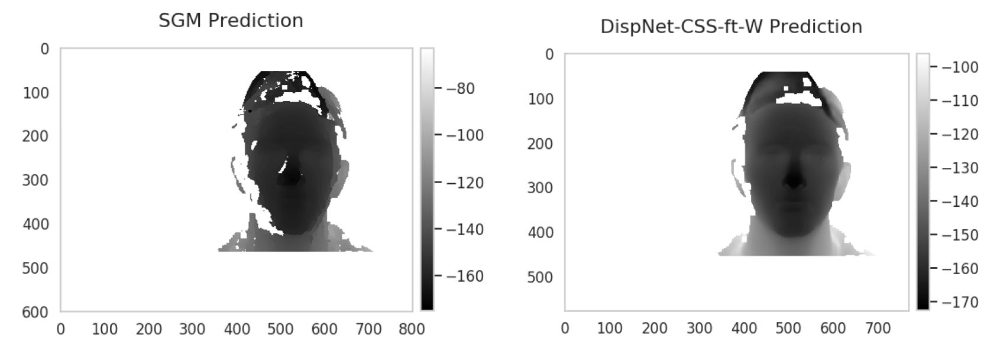
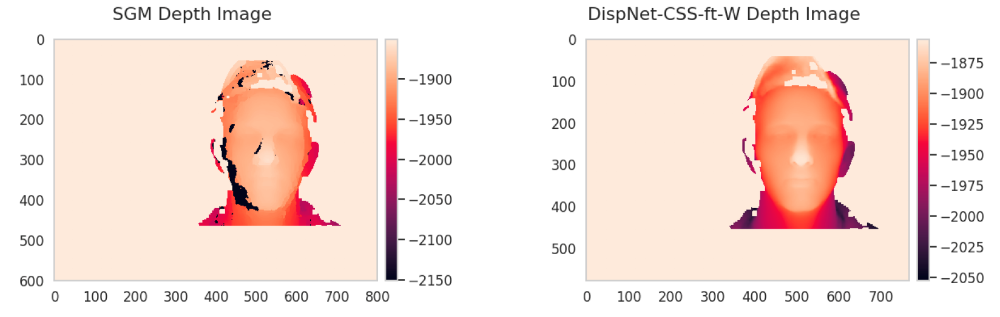
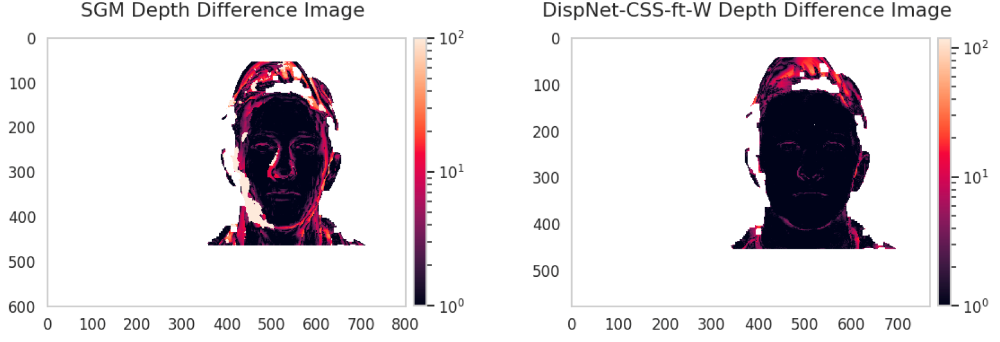
Generalization
Generalization capability describes the ability of the network, which is trained on one dataset, gives good prediction on another dataset. We compare the generalization capability of our network to a state-of-the-art multi-view depth estimation network, MVS-Net, on non-synthetic novel-setting facial images taken surround the face. Our network does not generalize well on the side-view images and this leads to a poor mesh result. By combining side-view disparity maps from SGM and front-view disparity maps from our network, the output mesh becomes better. On the other hand, MVS-Net generalizes well on the novel data and provides smooth and detailed face avatar.

References
[1] Moritz Menze and Andreas Geiger. “Object Scene Flow for Autonomous Vehicles”. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2015).
[2] Y. Kitajima G. Krathwohl N. Nesic X.Wang D. Scharstein H. Hirschmüller and P. Westling. “High-resolution stereo datasets with subpixel-accurate ground truth”. In: In German Conference on Pattern Recognition (GCPR) (2014).
[3] E. Ilg et al. “Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation”. In: European Conference on Computer Vision (ECCV) (2018).
[4] P.Hausser P.Fischer D.Cremers A.Dosovitskiy T.Brox N.Mayer E.Ilg. “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation”. In: In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
[5] Face Recognition Grand Challenge (FRGC). URL: https://www.nist.gov/programsprojects/face-recognition-grand-challenge-frgc.
[6] S. Li T. Fang Y. Yao Z. Luo and L. Quan. “Mvsnet: Depth inference for unstructured multi-view stereo”. In: ECCV (2018).
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter