
André Wiedemann
Intelligent Analysis and Creation of Training Data for Simple Object Detectors based on Convolutional Neural Networks
Duration of the Thesis: 6 months
Completion: November 2018
Supervisor: Dr. Florian Richter (Bosch Sicherheitssysteme GmbH)
Examiner: Prof. Dr.-Ing. Norbert Haala
Training convolutional neural networks (CNNs) from scratch requires hundreds of thousands of high-quality training samples - a crucial resource that is hard to attain. Manual labeling is expensive and often not an option. Furthermore, many detection tasks have been solved through cumbersome state-of-the-art CNNs; however, companies are often interested in smaller networks that allow for implementation on products.
We propose a scheme in which we use publicly available state-of-the-art networks to automatically generate a large set of high-quality training data for lean head-shoulder detectors based on very small fully convolutional architectures.

Automatic Labeling using State-Of-The Art Detectors
We first apply three state-of-the-art people detectors YOLOv3 [1], Mask R-CNN [2] and Pose Estimation [3] to a set of images and combine it with our own algorithms for extracting head-shoulder boxes from raw detections. Pose Estimation quickly proves to be our most valuable asset as it provides precise keypoints from which the most accurate head-shoulder bounding boxes can be derived. 93.3 % of all head-shoulder instances are correctly recovered by Pose Estimation, however, the set of initial automatic labels also contains 5.5 % false labels – too many for unfiltered use in detector training.

To eliminate false labels, we combine automatic head-shoulder labels of all three detectors in a majority vote setting. By doing so, we generate labels on image level with three possible annotations: positive (all detectors approved), ignore (some but not all detector(s) triggered) and negative (no detector triggered). Our majority vote setting practically eliminates all false labels while maintaining acceptable recovery of 79.1 %. From our image level annotations, we crop head-shoulders as positive samples and randomly sample background patches from negative regions to automatically generate a pure initial training set for patch-based detector training.
In-Training Data Enrichment
Despite having generated a clean training set, we see potential for further data improvement inside the training process.
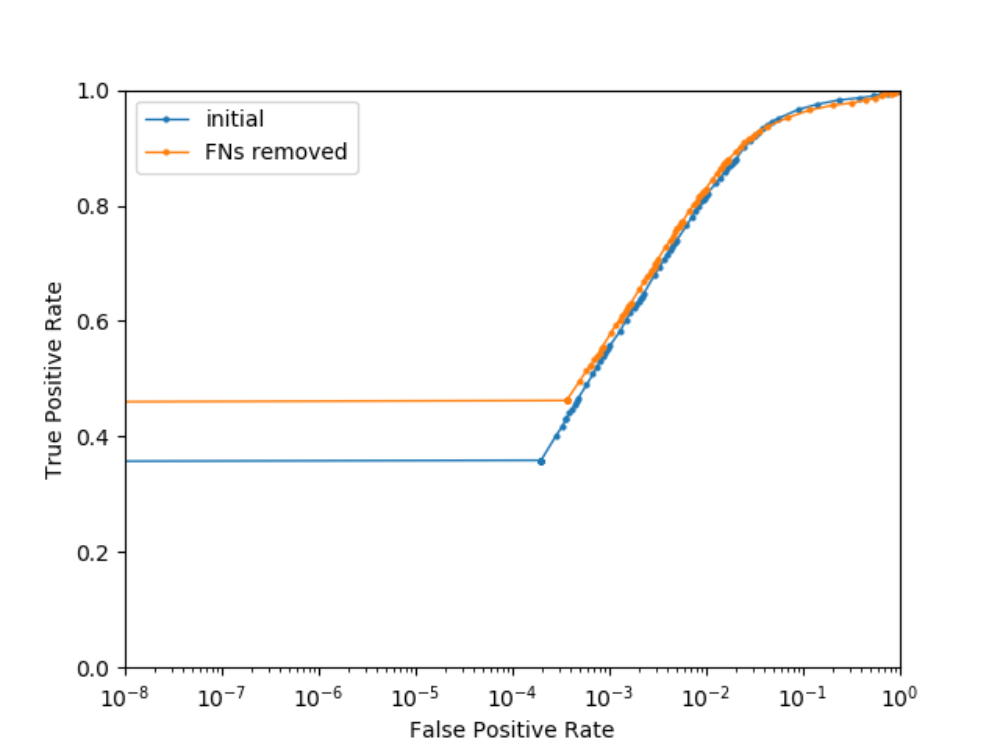
False Negative Filtering: First, we train a small network on the initial training set. Because the number of available parameters is strictly limited, the detector does not manage to fully separate all positive and negative training samples. The vast majority is correctly learned; however, when applying the detector to its training set, we find some false negatives. Looking at the falsely rejected positive patches, we notice that most of them are low quality head-shoulders – cropped, too tight or blurry. We remove all false negatives from the training set which further cleans our set of positive samples and repeat this process several times. As figure 3 shows, detector performance on unseen data is improved by false negative filtering; however, the effect is rather small because the set of initial positives is already very pure.
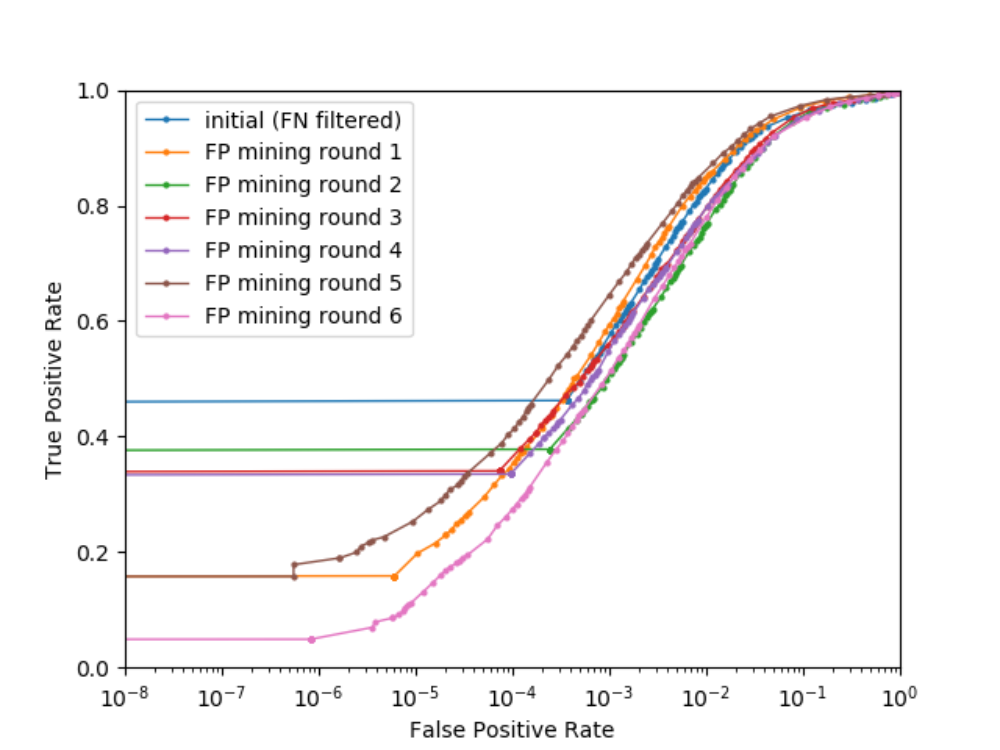
False Positive Mining: Secondly, we increase the information content of our set of negatives in a process we refer to as false positive mining. To keep a balanced training set, we randomly pick a small subset of all possible background patches for our training set. By applying a detector on the full images, we can extract false positives – those background patches falsely recognized as head shoulders. We notice that false positive samples contain much more edge information than our set of randomly sampled negatives. In several iterations we add false positives to our set of negatives and therefore give hard samples a stronger weight which causes the detector to generate less false alarms on unseen data. Figure 4 shows detectors trained on the initial training set and six rounds of false positive mining. The results fluctuate because of instable training as the number of hard negatives increases; however, round 5 achieves 10 % higher true positive rates than the detector trained on randomly sampled negatives with little information value.
Results and Conclusions
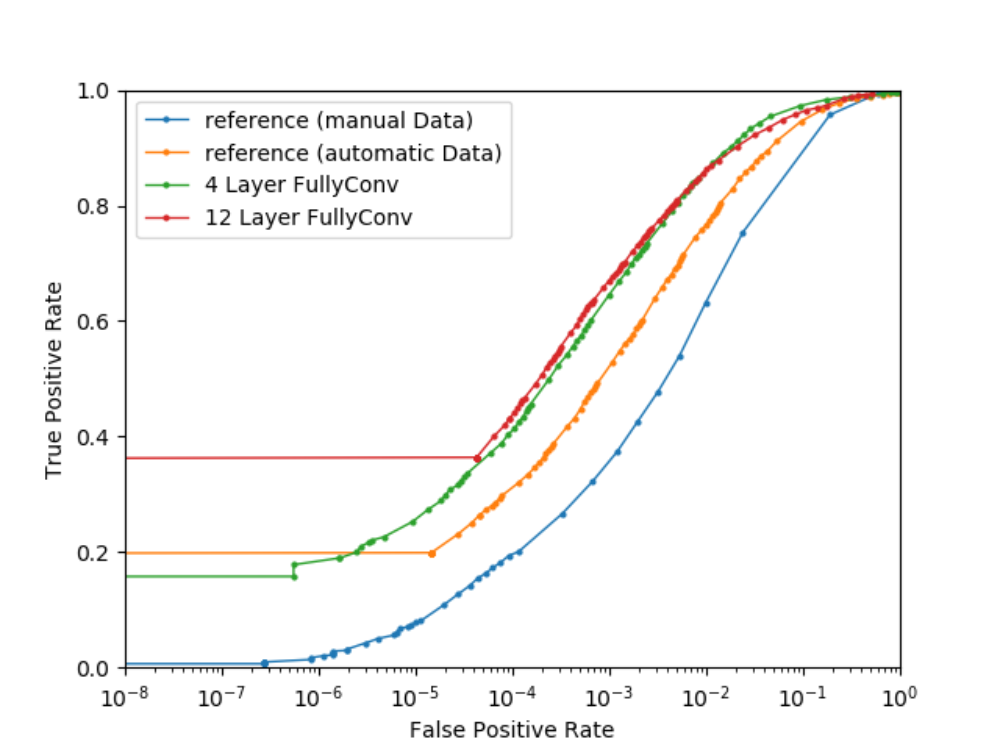
For final evaluation we train three different architectures on our automatically generated and enriched training set. First, a lean four-layer architecture for which a reference detector trained on pre-existing manual annotations is available. Secondly, a slightly modified architecture with about 20 % more parameters and lastly, a much larger 12 Layer architecture solely for test purpose as it is much too large for product implementation.
Figure 5 shows all detectors evaluated on an independent database. Solely by using our automatically generated instead of provided manual data, a reference detector achieves 10 % higher true positive rates for all relevant false negative rates. Slight modifications to the architecture cause the detector to perform 20 % better. Randomly increasing model size however, does not cause economically relevant improvement.
In our thesis we generated a high-quality training set without the need for any manual label whatsoever. Our automatic labeling and data enrichment process allows for generating arbitrarily large training sets at no labeling cost. Furthermore, we build a very small head-shoulder detector for product implementation that achieves 20 % higher true positive rates than a provided pre-existing detector.
We show that:
- Automatic labels can replace manual labels entirely for some detection problems
- Purity of training sets is crucial – especially when using small architectures
- Small networks can solve challenging detection tasks and randomly increasing a detector's complexity is not a universal solution to better performance
References
[1] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv
preprint arXiv:1804.02767, 2018.
[2] Kaiming He, Georgia Gkioxari, Piotr Doll_ar, and Ross Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 2980{2988. IEEE, 2017.
[3] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity felds. arXiv preprint arXiv:1611.08050, 2016.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter