
Joanna Dagmara Górska
POI Match Review - elimination of duplicates by applying automated classifier
Duration of the Thesis: 6 months
Completion: March 2018
Supervisor: Dr.-Ing. Volker Walter, Emmanuel Adetutu¹, Angel Prieto¹ & Grygoriy Rybalchenko¹ (¹ HERE Technologies)
Supervisor & Examiner: Prof. Dr.-Ing. Uwe Sörgel
Introduction
Duplicates in the databases are the problem of many companies that collects data coming from different sources. Identifying and filtering them helps to maintain the integrity of the data. Data filtering can be performed in manual, semi-automated or automated ways.
The purpose of this study was to develop an automated process that defines pairs of duplicates which refer to the same real entity – an EV (Electric Vehicle) charging station. Searching for duplicates is currently performed manually in Microsoft Access. Research is focused on the automation of the current POI (Points of Interests) classification rules. New classification rules are developed based on the sequential covering algorithm in the FME data integration software. The outcomes generated in the different approaches (manual and automatic) were compared. The basis of this research is a methodology called Rule Based Classification.
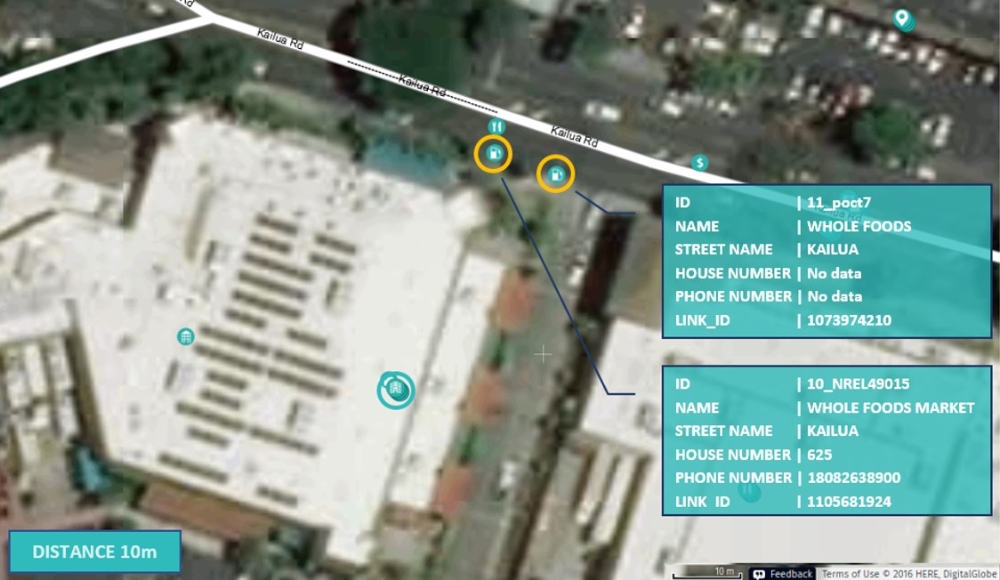
POI - Match Review
Match Review stage is the most time-consuming part of the Rich Content process. Currently, this manual activity lasts around 2 hours for POIs that cover area of North America. Moreover, filtering duplicates involves human expertise and the manual processes are error-prone. The next weaknesses of this operation are results which cannot be recreated, due to different decisions of operator during Match Review. This is caused by the subjective nature of the classification that is performed in the manual review and affects the consistency of the product between different releases. Consequently, it has an influence on the quality of the product.
To improve the Match Review process, it was necessary to rebuild classification rules in the Match Review process and automate it to minimize human work in clerical review.
Methodology – Rule Based Classification
Rule Based Classification is a classification technique which describes the relationship between conditional attributes and decision attributes, using the implications: conditions expressed in a logical formula on the left-hand side, and the value of the decision attribute on the right-hand side. Rule can be written in the form (Han & Kamber, 2006):

Results
During the research data generated in 4 different approaches were compared:

The analysis shows differences between different approaches for manual and automatic classification. Manual approaches are more flexible in terms of evaluation and classification of pairs of records. Therefore, manual classification filters more pairs of records than automatic approaches for classification rules requiring expert assessment. However, manual approaches also classify pairs of records that do not fulfill classification rules. This is due to mistakes made by operators. The change of classification rules from current to new in the automatic approach resulted in more POI pairs being correctly classified as match pairs. This proves that the new rules have become more effective with this approach.
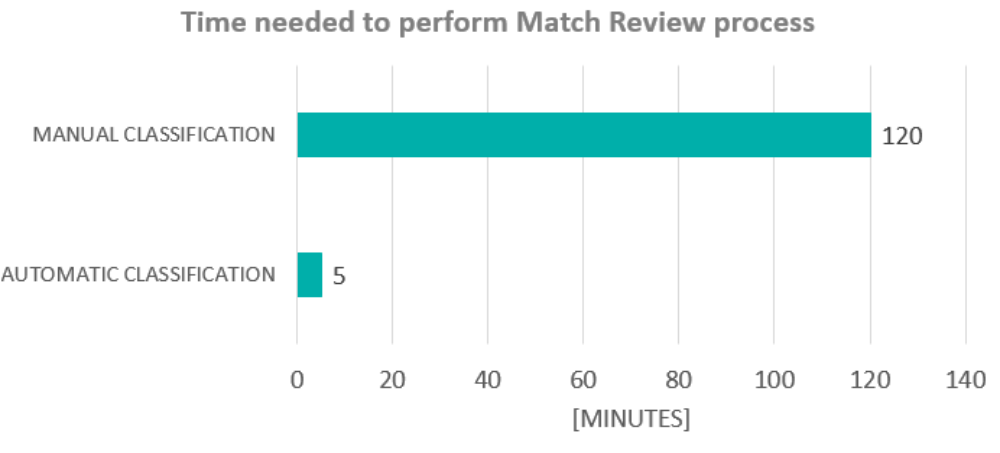
Datasets generated in manual and automatic approach differ from each other not only in terms of the number of selected pairs of duplicates, but also in terms of time required to perform the task.
Conclusions
Detection of duplicates in the databases is a relevant task in the maintenance of good data quality, especially in today’s world, where the amount of data grows exponentially. Therefore, solutions that are responsible for finding and deleting matching records should be reliable and fast.
This research focuses on the improvement of a manual process that involves detection of duplicated POIs. This has been done by the application of an automatic classifier.
The automatic classifier was designed to detect duplicates of POI objects - EV stations - between source data and data already contained in the database. This was not a simple operation due to the lack of characteristics describing POI, in other words a key attribute that would refer to a specific EV station.
This problem has been overcome by using a classifier based on the Rule Based Classification methodology. It allowed the development of a combination of classification rules based on currently available POI attributes, which enabled selection of duplicate pairs.
During the research, current classification rules were automated and the new classification rules proposed. Automatic processes generated results close to the outcomes achieved in the manual classification and they were within a defined margin of error.
The research focused on finding answers to the questions of whether the current process is optimal, whether this process can be automated and whether the chosen methodology to improve the process produce the expected results.
The analysis proved that the current process is not optimal. This is caused by the fact that the process is manual and error prone. Another drawback of the current process is the time needed to complete it. Furthermore, it is not possible for the operator to reproduce identical results. The solution to the issue was an attempt to automate the process and eliminate the human factor. Analyses demonstrated that automation can generate results similar to those achieved by the operator, which proves that automation was possible. Moreover, the significant benefit of automation was that the time needed to perform the process has decreased more than twenty times and the repeatability of the generated results has been achieved.
References:
Han, J. and Kamber, M. (2006). Data Mining: Concepts and Techniques. 2nd ed. San
Francisco: Morgan Kaufmann Publishers.
Ansprechpartner

Uwe Sörgel
Prof. Dr.-Ing.Institutsleiter, Fachstudienberater