Hao Pang
Application of Machine Learning Algorithms for the Automatic Recognition of Characters in Scanned Survey Plans
Duration of the Thesis: 6 months
Completion: June 2017
Supervisor: T. Heuchel (Trimble/Inpho) and Dipl.-Ing. Patrick Tutzauer
Examiner: Prof. Dr.-Ing. Norbert Haala
Pipeline of the Whole Process
The innovations and breakthroughs in the domain of machine learning in recent years have provided a glimpse of a new dawn in artificial intelligence. Neural networks have become the essential tool allowing machines to make sense of the world. By learning from the data fed into them they enable computers to make decisions and predictions with a degree of probability.
This thesis focuses on the first step of incorporating the significant innovation of machine learning into the understanding and batch processing of a land survey plan in image form, in cooperation with Geospatial Division, Inpho/Trimble Germany GmbH and the Institute for Photogrammetry at the University of Stuttgart. It describes the creation of a program designed to enable computers to detect and recognize some of the measured values from land survey plans using modern machine learning algorithms and the corresponding programming frameworks.
To obtain explicit semantic meaning and avoid post-processing phase , this approach is modified to detect all 9 or 10 digits in a sequence simultaneously rather than one at a time with rectangle detection masks. The patterns around the digits, especially the shorter sequences with exactly the same font, color, size, and distribution, are therefore expected to cause serious external disturbances.
Problem Statement
The goal of this section is to present a framework of the proposed program with respect to the four essential challenges mentioned in the main text. The program consists of three fundamental parts: a synthetic image engine, a training processor, and a detector.
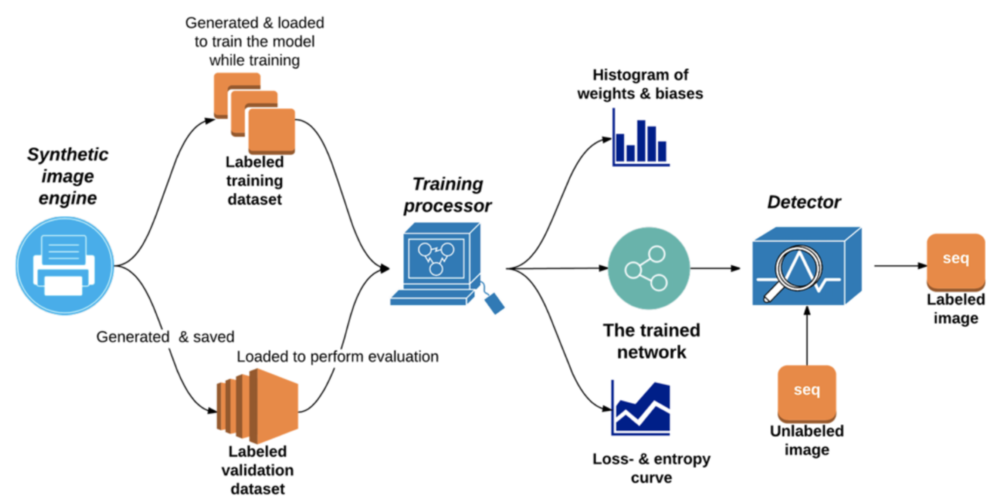
The synthetic image engine is responsible for rendering image data which adequately simulates the sequences in real survey plans with randomly variable size, orientation, shifting, buffer, and background textures. It can produce and save abundant amounts of labeled image examples at high speed. The resulting gray-scale images measuring 64×128 pixel are used to train the neural network and evaluate accuracy during training.
The training processor is primarily capable of training the network, in other words it tunes the parameters in each of the network’s neural cells slightly during training, gradually making it able to respond to new input images with reasonable predictions. After training, it hands over all parameters to the detector. Secondly, it saves the changing curve of several essential indicators which can describe and evaluate the current training process.
The detector executes detection, segmentation, and recognition functions on an entirely unknown image with a sliding mask. As it shifts it locks the locations of all detected sequences and prints the corresponding predicted values on an output image.
Structure of the training network
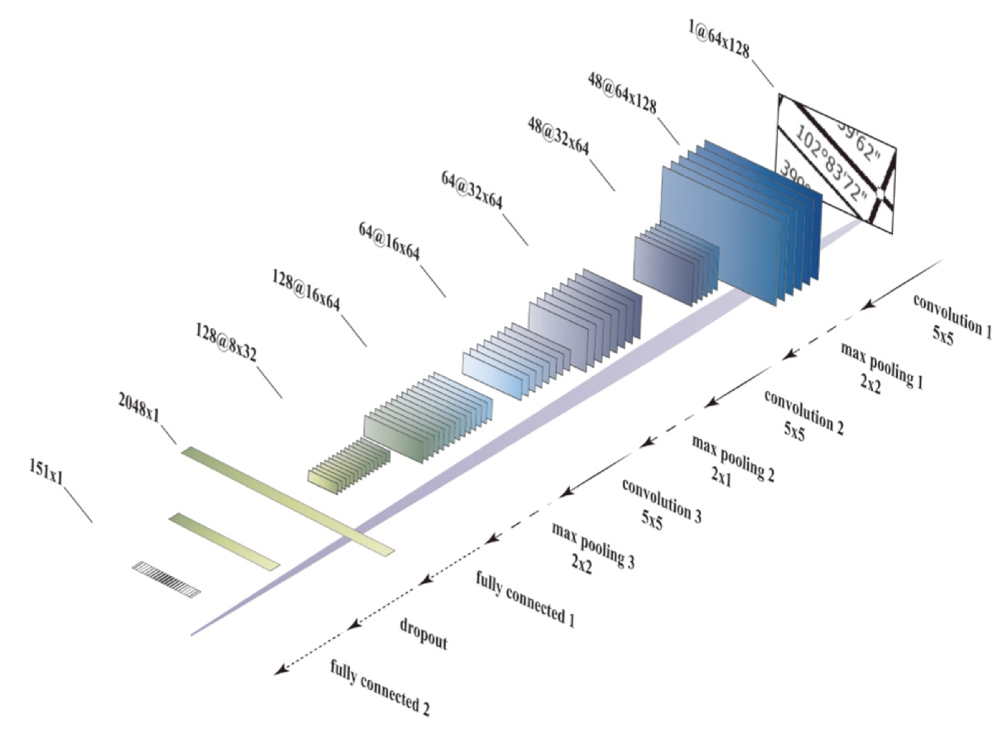
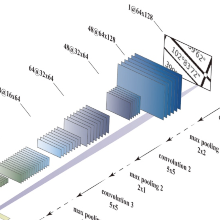
The prototype of the deep network employed in this approach is the network designed by Stark et al. (2015) for CAPTCHA-recognition. It contains three convolutional layers and two fully connected layers, with a dropout layer in between.
Test Results of detection
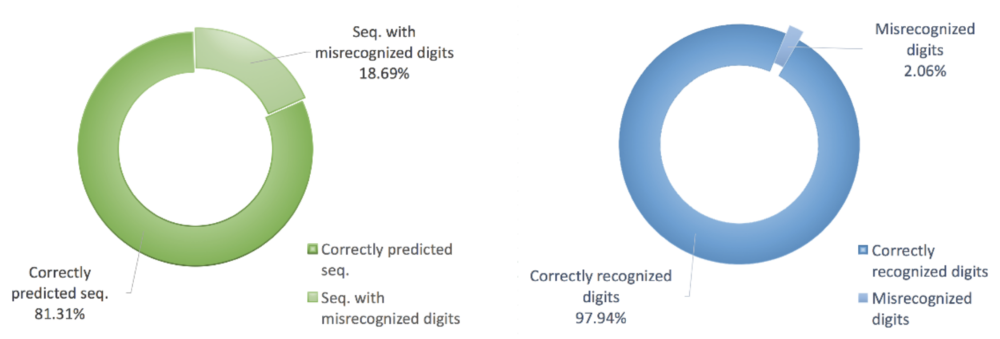
The ring charts in the following display graphically the percentage of all correctly predicted sequences and successfully recognized digits respectively:
Conclusion
In this thesis, we successfully implemented a machine-learning algorithm for sequence recognition in land survey plans. Rather than adopt a feature-based OCR algorithm, our approach simultaneously addressed three basic recognition subtasks – localization, segmentation, and recognition – by employing a deep CNN.
After evaluation using an extensive number of real-world images, we fully proved that our system is capable of quick, stable sequence detection and recognition. The precision of sequence localization and the accuracy of digit classification reached 91.58% and 97.94% respectively in the real-world test dataset, which represents encouraging progress in this domain. Both the precision of sequence localization and the accuracy of digit recognition were of satisfactory levels.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter