
Manohar Erikipati
Implementation and comparison of content based image retrieval methods
Duration of the Thesis: 6 months
Completion: November, 2015
Supervisor & Examiner: Dr.-Ing. Volker Walter
Abstract
Modern technology made storing, sharing, curating huge amounts of data easy through the internet of things. Search engines and query based retrieval databases made access to relevant data easy through ranking and index basing on content stored. This works optimally with text based information systems. In conventional image1 databases, images are stored along with individual metadata, this metadata includes tags and keywords which are used for text based search for relevant image retrieval. Maintaining an image database basing on human annotations is a tedious and clumsy task. We need intelligent Content based image retrieval technics that eliminate the problems associated with annotations, search tags et cetera and also anchor upon image content than on manual methods. For this purpose various expert technics are proposed in science journals basing on wide variety of factors such as color, texture, shape, faces, fingerprints and spatial layout.
Modern image databases have various types of algorithm based feature vector extraction from images, these feature vectors are then compared and distance between these features vectors are considered as index of similarity. For various types of applications in different fields of studies, several content based image retrieval methods have been proposed in science journals for research and development in this area. Most popular implementation of this content based image retrieval is Google image search with input as image instead of a query.
As part of my thesis, I have implemented several feature extraction algorithms. These algorithms are used for feature extraction of images, a comparison is made between these extracted features, a distance score is calculated and images are sequenced based on their similarity. The results of these algorithms are implemented individually and in weighted combination with each other and results are evaluated. There are a vast number of CBIR2 implementations for various kinds of applications basing on extraction and comparison of different types of image content. The visual content can be anything photographed or digitally produced and images consists various kinds of distortions. A perfect image is undefined. In a set of images, to compare each other we need to find relationships between the image objects. The above factors can sometimes help in finding those relationships and sometimes can have negative impact on the process. A balance of weightage between various factors should be sought after for comprehensive content based image retrieval. The aim of this master thesis is to study, implement algorithms to cover the fundamental properties of images such as color, shape and texture. The images in the database are sequenced based on similarity with respect to a user chosen principle image from the database.
Theory & Literature
CBIR is also termed as “Query by image Content”. The idea behind CBIR is to develop an automated process to find information inside a digital image irrespective of how it is named or tagged or text-annotated. To achieve a working CBIR system, we need to develop algorithms to extract unique feature data from images. This feature data can be compared and index of similarity between images can be established.
In the master thesis we discuss the advent of large image databases, annotation based search engines, early CBIR systems and proposed implementations in science journals. We also discuss about the applications of CBIR systems.
Implementation
Graphical User Interface
A graphical user interface was developed to assist the user in executing algorithms and performing visualization of results. Radio buttons are used to select the algorithms.
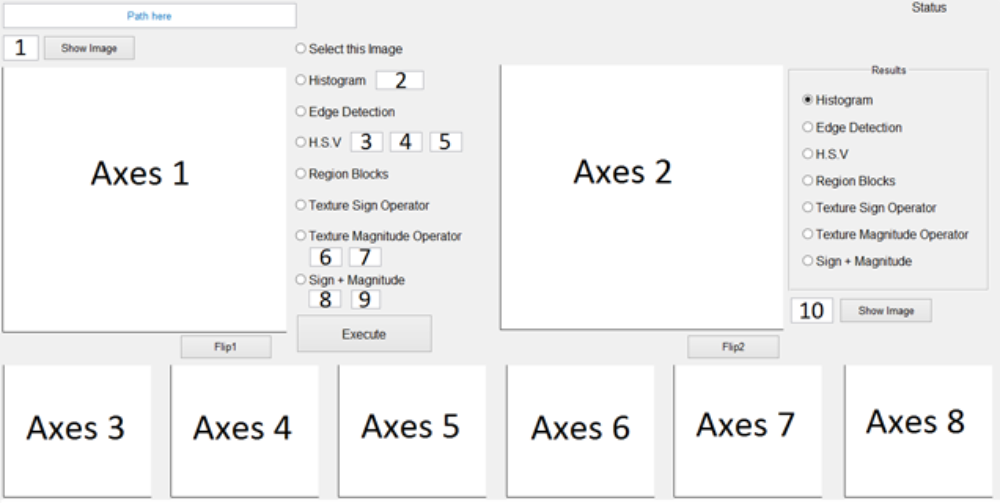
In the Figure 1, we can see the GUI elements present in the matlab GUI implementation of this thesis.
Data Acquisition
The aim of the thesis is to use images with common context, apply CBIR algorithms to use with respect to a chosen image and compare the results of these algorithms. These algorithms are used to exclude out the target feature content of an image and use this feature data to compare with each other to sequence images in order of similarity. To have images with common context though, one of the easiest ways to acquire these images is to download them from search engines for a specific search query. Google image search results are used in this Master thesis as image database.
Algorithms
meanRGB
This is the most common comparison of images basing on color. I have implemented this by dividing an image into 256 equal parts and obtaining mean RGB value of each part to build feature vector for each image. Then Euclidean distance was calculated between these feature vectors to determine histogram similarity.
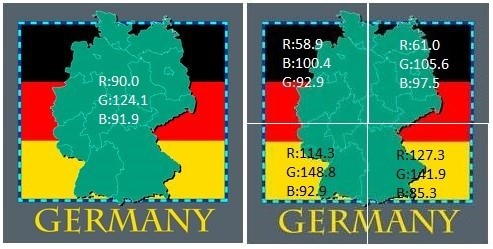
Figure 2: Whole image mean RGB vs. mean RGB of parts
Matlab code for Histogram allows the user to input any number to divide the image into, making it easier to compare results from images segmented into 64, 256 and 4096 etc.
Edge detection
Using Sobel method, the edge detection is performed on images in the database and then using above method, images are segmented and mean grey values are estimated and are stored in feature vectors for comparison. Figure 3 shows the example result of edge detection algorithm on a germany map image.
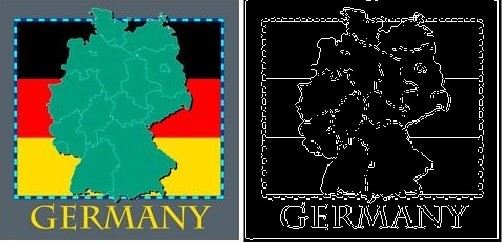
Figure 3: Edge detection binary image output for the example image
H.S.V
Hue, Saturation and Brightness value comparison is made by converting the RGB image into a HSV image of type double in Matlab, classify Hue, Saturation and Brightness values in given number of classes, a unique feature vector is generated.
Color Regions of Interest
Usually in an RGB image containing map data, each object is represented in a unique color (Ex: Land surface, vegetation, water bodies, roads, borders). This specific color difference can be obtained using a Watershed segmentation of Histogram and selecting the right region of interest compare shape of the image objects.
- 6 different color regions are extracted from the image and using color values in the area of the image, right region is determined.
- For maps I have taken middle image part color values, if they exist they are used so as to exclude other countries, borders etc.
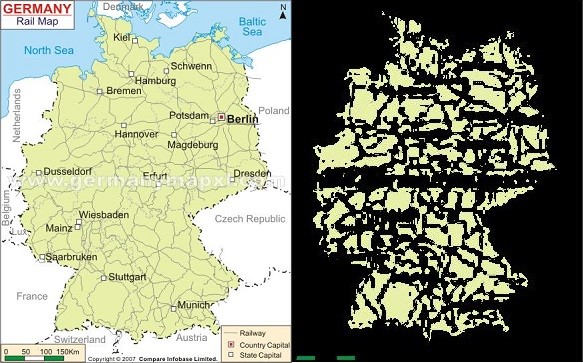
Figure 4: Original image and output region image
Texture sign operator
This is an implementation of “Expert content-based image retrieval system using robust local patterns” proposed by Subrahmanyam Murala and Q.M. Jonathan Wu (2013).
Each middle pixel and its neighboring 8pixels are compared in grey scale. If the neighboring pixel grey value is higher than the middle pixel then it is given a Boolean value 1, if it is lesser then 0. So we get a unique texture distinguished vector which we can use to compare images (Euclidean distance). Most roads, railway lines are distinguished by this method.
Texture Magnitude operator
This is an implementation of “Expert content-based image retrieval system using robust local patterns” proposed by Subrahmanyam Murala and Q.M. Jonathan Wu (2013).
Every 9 pixel set mean grey values are compared to the total mean grey value of the image in grey scale. If the pixel set has higher grey value, the pixel are assigned a value 1 otherwise 0. This is executed with weighted coefficients for each 9pixel set and a unique texture vector is calculated to compare by Euclidean distance.
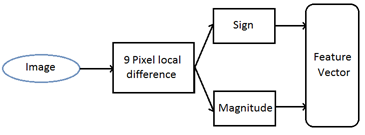
Figure 5: Flowchart for sign and Magnitude algorithms
The flowchart in the Figure 5 shows the workflow of sign and magnitude algorithms.
Figure 6: Original image and output image from sign operator
Evaluation
For an implementation such as this, we need few constants to follow to have an accurate data retrieval analysis. In the evaluation chapter we discuss about the constants we use to implement the Master thesis.
Using 2 or more of these methods in tandem on weights of importance, the sequence of images achieved are compared. Each method is compared and analyzed with each other.
Discussion
We discuss the success of algorithms comparing with the number of segmentations and classifications used. The edge detection algorithm worked the best when compared to all other algorithms. But in the experimental tests with images of different contexts, the colour algorithms and the sign operator worked best in images with unique colour and texture tones.
Based on the results and discussion, as addition to the thesis an outlook is presented which include probable solutions for the problems faced in the image retrieval using these algorithms and to automate the process of algorithm selection for certain image contexts.
Ansprechpartner

Volker Walter
Dr.-Ing.Gruppenleiter Geoinformatik