David Collmar
Erstellung einer GUI zur crowd-basierten Digitalisierung von Objekten sowie Analyse der dadurch erhaltenen Daten
Dauer der Arbeit: 4 Monate
Abschluss: September 2018
Betreuer: Dr.-Ing. Volker Walter
Prüfer: Prof. Dr.-Ing. Uwe Sörgel
Motivation
Das Internet ist sowohl für Unternehmen als auch Privatpersonen inzwischen längst mehr als nur ein Kommunikationsmittel, sondern ein Medium mit hohem monetärem Potential. Auch die Übertragung von klassischen Unternehmensfunktionen an externe Gruppen kann über das Internet erfolgen. Ein solches Outsourcing an eine große Gruppe in Form einer öffentlichen Ausschreibung, wie es beispielsweise über das Internet möglich ist, wird „Crowdsourcing“ genannt. In dieser Arbeit wurde das Potential des „Crowdsourcing“ zur Digitalisierung von Gebäudepolygonen in Orthofotos untersucht. Zusätzlich wurde noch überprüft, ob fehlerhaft digitalisierte Datensätze automatisch erkannt werden können.
Vorgehensweise
Zur crowd-basierten Erfassung von Gebäudepolygonen musste zuerst ein für die sogenannte „Crowd“ zugängliches Digitalisierungstool erstellt werden. Dieses wurde in Form einer web-basierten grafischen Benutzeroberfläche (GUI) umgesetzt. Realisiert wurde die GUI mit HTML und CSS zur Darstellung, JavaScript zur Verarbeitung von Funktionen auf „client side“, PHP zur Verarbeitung von Funktionen auf „server side“ und AJAX zur Übertragung und Veränderung der Daten ohne Aktualisierung der Webseite.
Die GUI ermöglicht das Digitalisieren von Punkten auf einem HTML canvas-Element. Durch Klicken auf das canvas-Element können Punkte gesetzt werden, einige Buttons bieten noch Funktionen zur Bearbeitung der Polygone an. Weitere Komfortfunktionen wie „rubber bands“ oder das Verhindern des Schnitts zweier Linien des Polygons wurden zusätzlich implementiert.
Nach Bearbeitung kann der Erfasser anonymes Feedback hinterlassen und die Daten speichern. Die erfassten Daten werden automatisch auf dem Server gespeichert.
Nach Erstellung des Digitalisierungstools wurden über die Crowdsourcing-Plattform www.microworkers.com Erfassungskampagnen gestartet. Dazu wurden 15 Testobjekte im Stuttgarter Stadtgebiet ausgewählt, welche von je 25 Erfassern digitalisiert werden sollten. Anschließend erfolgte eine manuelle Sichtung und Prüfung der eingereichten Daten, um jene Datensätze auszusortieren, die nicht gemäß der Aufgabenstellung bearbeitet wurden. Bei fehlerhafter Bearbeitung musste die Erfassung wiederholt werden. Insgesamt ergab sich so eine Zahl von 375 korrekten Erfassungen und 113 fehlerhaften Erfassungen.

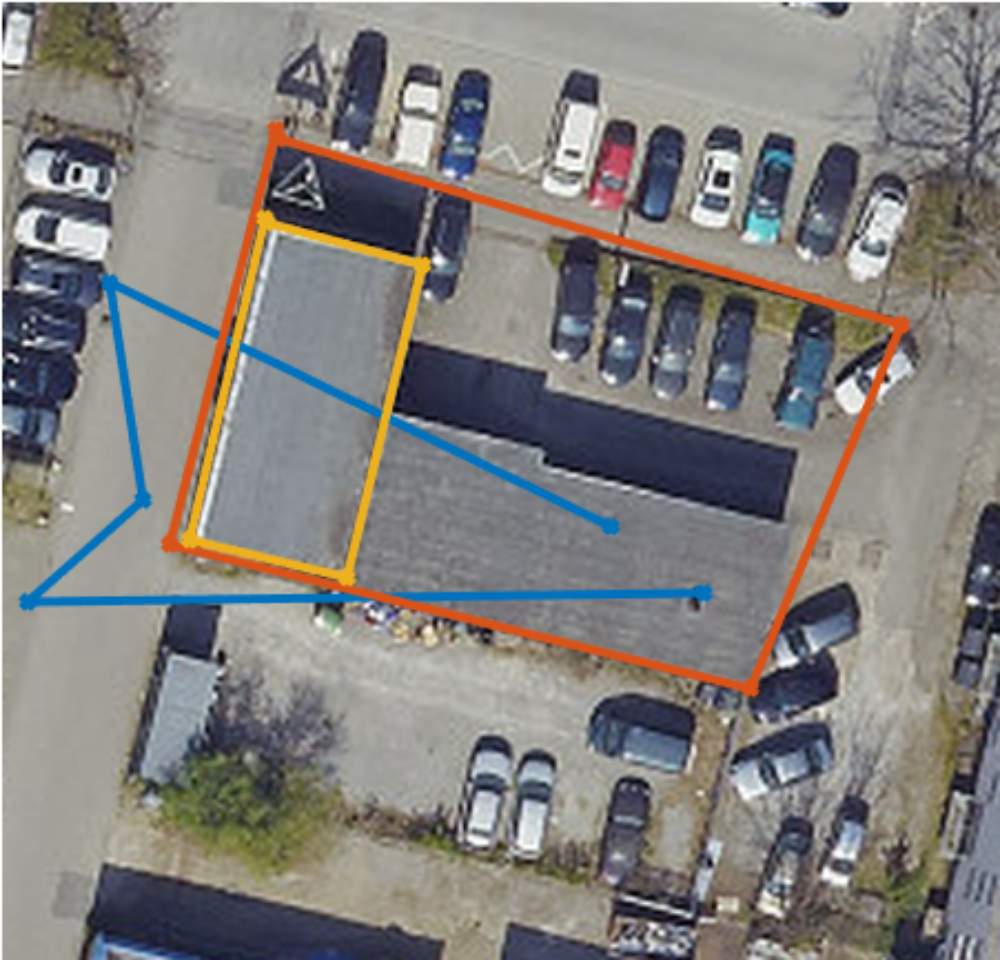
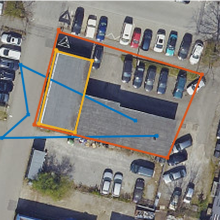
Nach Sichtung der Datensätze wurde eine automatisierte Auswertung mit anschließendem Vergleich mit der Referenz durchgeführt, um Rückschlüsse auf die Genauigkeit ziehen zu können. Dabei wurden die Parameter Punktzahl, Umfang, Fläche, Hausdorff-Distanz und geometrischer Schwerpunkt untersucht. Es stellte sich heraus, dass scheinbar kein Zusammenhang zwischen erreichter Genauigkeit und dem Parameter Punktzahl besteht, weshalb der Parameter Punktzahl in dieser Zusammenfassung außen vor gelassen wird.
Im ersten Schritt wurden nur die korrekten Erfassungen überprüft. Hier konnte bereits eine hohe Genauigkeit der Daten erkannt werden, da die Abweichungen zur Referenz im einstelligen Prozentbereich bzw. im Zentimeterbereich lagen:
- Durchschnittliche Referenzabweichung Umfang: 2,91%
- Durchschnittliche Referenzabweichung Fläche: 5,44%
- Durchschnittliche Referenzabweichung Hausdorff-Distanz: 35,1 cm
- Durchschnittliche Referenzabweichung Geometrischer Schwerpunkt: 77,7 cm
Beispielhaft sind die Histogramme der Abweichung des Umfangs der Erfassungen zur Referenz zu sehen, hier einschließlich zurückgewiesener Erfassungen.
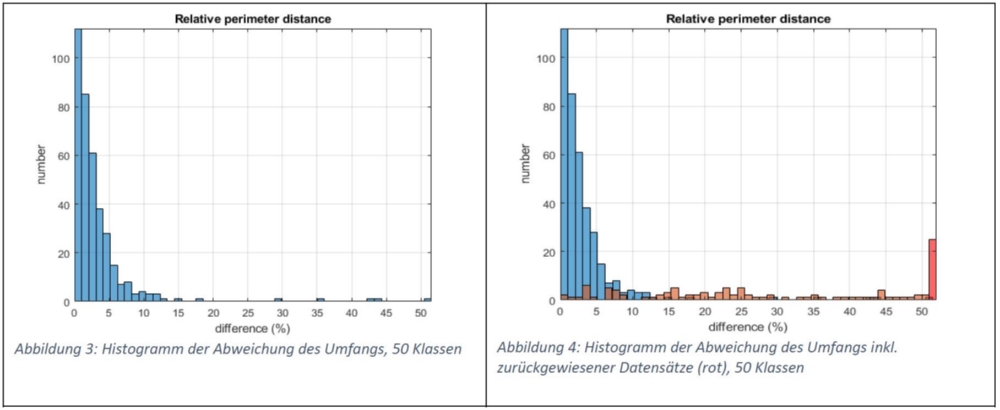
Anschließend wurde untersucht, ob fehlerhafte Erfassungen automatisch erkannt werden können. Dabei wurden lediglich einfache statistische Methoden angewandt. Beispielsweise wurde ein Quantil gewählt, in welchem einzelne Erfassungsparameter liegen sollten.
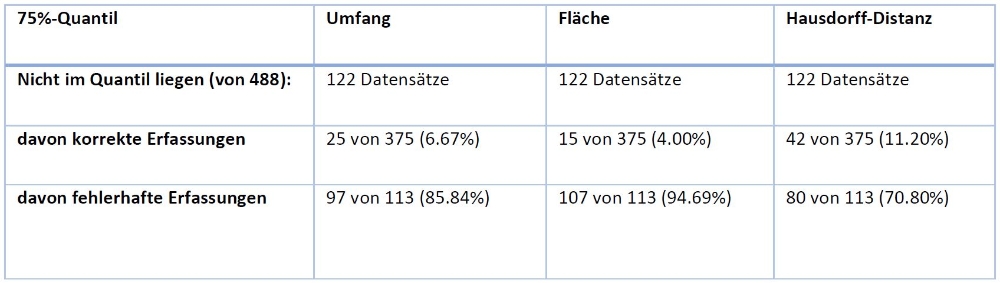
Es konnte festgestellt werden, dass sich vor allem die Fläche zur Detektion von fehlerhaften Erfassungen eignet. Trotzdem waren die Ergebnisse noch nicht zufriedenstellend, weshalb eine weitere Methode gewählt wurde: Durch Verknüpfung dieser Parameter („welcher Umfang und welche Fläche liegen innerhalb des Quantils“) konnten die Ergebnisse weiter verbessert werden.

Mit einem Verlust von lediglich 10% der korrekten Datensätze lassen sich also fast alle fehlerhaften Datensätze nur durch einfachste statistische Methoden, der Verknüpfung von Umfang und Fläche, bestimmen. Werden weitere Parameter hinzugenommen oder das Quantil kleiner gewählt, werden noch mehr fehlerhafte Datensätze eliminiert, allerdings auch mehr korrekte Datensätze, wie in folgender Tabelle zu sehen.

Eine „beste“ Methode kann allgemein nicht beschrieben werden, da sie vom Anwendungsgebiet abhängig ist: Sollen gezwungenermaßen alle fehlerhaften Erfassungen erkannt und aussortiert werden? Sollen möglichst viele korrekte Erfassungen erhalten bleiben? Soll ein optimaler Mittelweg gewählt werden?
Somit sollte je nach Aufgabengebiet manuell eine entsprechende Wahl der Verknüpfungsparameter und des Grenzquantils gewählt werden.
Ergebnisse und Fazit
Die entwickelte GUI konnte von den Crowdworkern problemlos verwendet werden. Lediglich eine der 52 übermittelten Feedback-Dateien enthielt negatives Feedback, 42 dagegen positives Feedback. 113 Datensätze mussten zurückgewiesen werden, was knapp einem Viertel der Gesamterfassungen entspricht. Es konnte festgestellt werden, dass die Punktzahl kein gutes Genauigkeitsmerkmal ist, allein durch Betrachtung der Fläche allerdings schon ein Großteil der Erfassungen aussortiert werden kann. Durch Anwendung von einfachen Operationen wie dem Aussortieren von Datensätzen anhand der Wahl eines Quantils lässt sich bereits ein Großteil der fehlerhaften Erfassungen eliminieren, da es sich in der Regel um Ausreißer handelt. Durch Verknüpfung der Quantilauswertung einzelner Parameter lässt sich die Genauigkeit noch deutlich verbessern.
Die manuell akzeptierten Datensätze weisen eine hohe Genauigkeit auf, eine automatisierte Sortierung führt zu ähnlichen Ergebnissen in Hinblick auf die erreichte Genauigkeit. Wird also eine Möglichkeit zur Eliminierung von fehlerhaften Datensätzen, manuell oder automatisiert, angewandt, so lässt sich durch Crowdsourcing eine gute Datenqualität bei Erfassung von flächenhaften Objekten in Orthofotos erreichen.
Ansprechpartner

Volker Walter
Dr.-Ing.Gruppenleiter Geoinformatik