Jingtong Li
Hierarchische graphbasierte Analyse und Klassifikation von Siedlungsstrukturen
Dauer der Arbeit: 6 Monate
Abschluss: März 2017
Betreuer: Dr.-Ing. Susanne Becker
Prüfer: Prof. Dr.-Ing. Norbert Haala
Motivation
Heutzutage werden immer mehr räumliche Daten erfasst, z.B. Luftbilder, topographische Karten und digitale Geodaten aus dem AAA-Modell. Es bedarf daher Wergzeuge zum schnellen und präzisen Zugriff relevanter Informationen. Dabei rufen die Informationen der Siedlungsstrukturen bezüglich ihrer Landnutzung bei vielen wissenschaftlichen und planerischen Untersuchungen besondere Interessen hervor, da sie für viele weitere Untersuchungen verschiedener Bereiche als Grundlage dienen. An solchen Informationen mangelt es derzeit leider den meisten Datengrundlagen. Und die bestehende Lücke fehlender Verfahren zur Gewinnung dieser Informationen ist noch zu schließen. In dieser Arbeit wird ein Verfahren vorgestellt, um hochwertige Informationen bezüglich der Landnutzung aus unstrukturierten räumlichen Daten zu gewinnen.
Als Eingangsdaten dienen die Gebäudegrundrisse aus dem ALKIS®, wobei nur die Verteilung und morphologische Eigenschaften von den Gebäudegrundrissen verwendet werden. Die Informationen der entsprechenden Landnutzungen sind in den Referenzdaten aus „Urban Altas“ enthalten. Mithilfe des in dieser Arbeit entwickelten Verfahrens soll die Nutzungsart bestimmter Gebäude anhand der Referenzdaten klassifiziert werden.
Vorgehensweise
Insgesamt besteht das Gesamtverfahren aus einer hierarchischen Segmentierung und eine nachfolgende überwachte Klassifikation. Im ALKIS® werden die Daten in Form von Einzelgebäuden repräsentiert. Zur Analyse und Interpretation der Siedlungsstruktur sollen zuallererst alle individuellen Einzelgebäude nach bestimmten Kriterien zu homogenen Gruppen übergeordneter Strukturen zusammengefasst werden. Dafür wird in dieser Arbeit das hierarchische Clusterverfahren angewendet, das von Anders et al. (1999) bzw. Anders & Sester (2000) entwickelt wurde. Bei diesem Verfahren werden alle Einzelgebäude durch Knoten ersetzt. Danach lassen sich verschiedene Nachbarschaftsgraphen aus den Knoten erzeugen, wobei sich eine Hierarchie davon bildet. Und alle Kanten einer niedrigen Hierarchiestufe sind in einer höheren Hierarchiestufe enthalten.
Am Anfang wird jeder Knoten als ein Cluster initialisiert. Nach bestimmten Ähnlichkeitskriterien, die durch Länge der Kanten zwischen den Knoten realisiert sind, können Cluster vereinigt werden. Nach der Gruppierung der Knoten in einer Hierarchiestufe werden die Kanten, die ausschließlich in der nächsten höheren Stufe enthalten sind, dazu hinzugenommen. Dadurch können bestehende Cluster bei einer Hierarchiestufe immer in größere Cluster vereinigt werden.
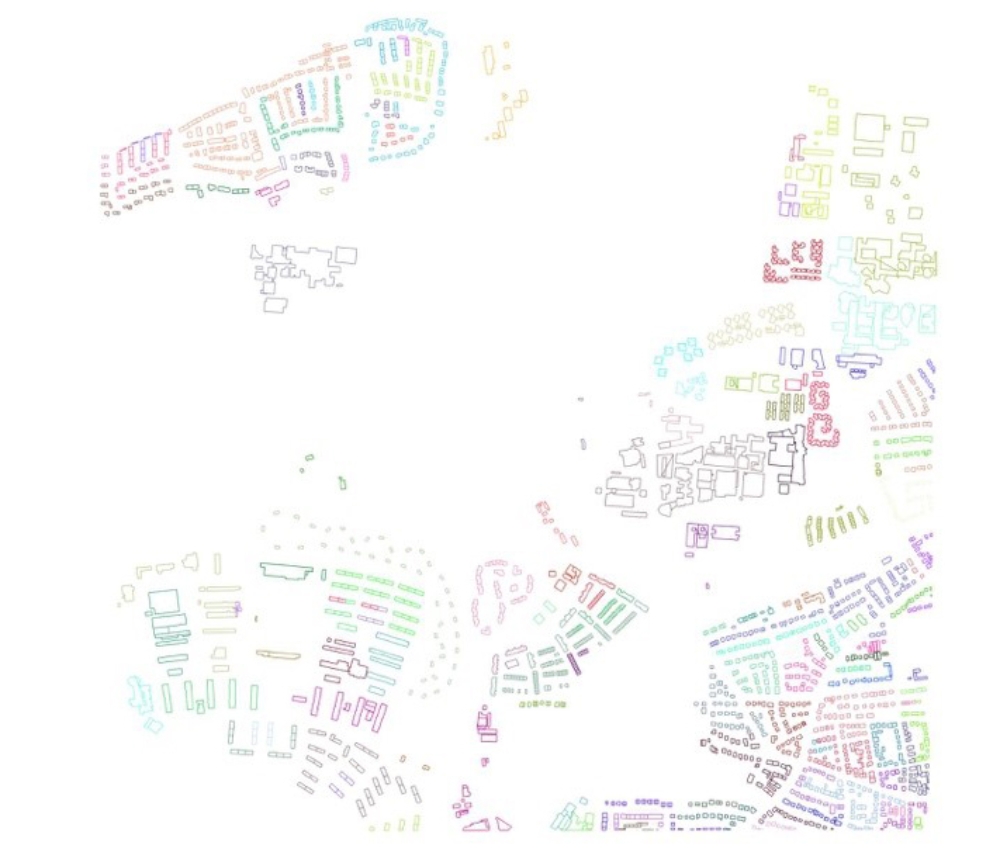
Da das oben beschriebene Clusterverfahren die Form von Gebäudegrundrissen nicht berücksichtigt, soll das Verfahren deswegen zur Anpassung homogener Form von Gebäudegrundrissen innerhalb der Segmente erweitert werden. Wenn sich die Clusteranzahl nicht mehr verringert, bekommt man die homogenen segmentierten Siedlungsbereiche.
Nach der Durchführung dieses Clusterverfahrens soll eine Klassifikation erfolgen. In dieser Arbeit wird der Random Forest Algorithmus angewendet, da er sich schon bei vielen Klassifikationsproblemen in anderen Arbeiten durch seine hohe Genauigkeit und weniger Laufzeit auszeichnete. Ein Wichtiger Vorteil dieses Algorithmus für die Untersuchung in dieser Arbeit ist, dass er die Wahl der wichtigsten Merkmale ermöglicht. Aus diesem Grund sollen zuerst möglichst viele Merkmale von den segmentierten Siedlungsbereichen berechnet werden. Diese Merkmale unterscheiden sich durch ihre Typen und ihre räumlichen Bezugsebenen und bilden zum Ende ein vollständiges Merkmalsset.
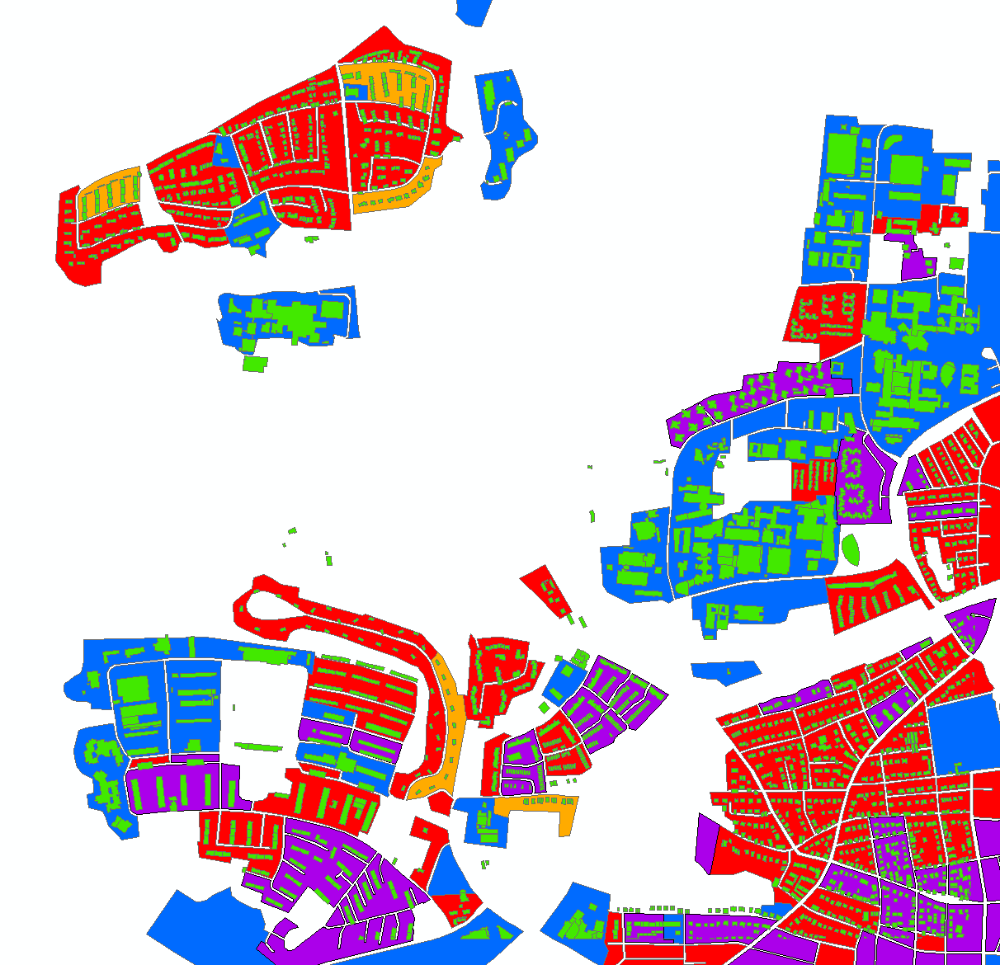
Von den Referenzdaten werden insgesamt drei Klassen von Landnutzung für die Klassifikation eingesetzt, Kontinuierliche Wohnsiedlung, Diskontinuierliche Dichte Wohnsiedlung und Nichtwohnnutzungsgebiet. Jeder segmentierte Siedlungsbereich wird einer Klasse davon zugeordnet. Durch die drei bekannten Klassen und das Merkmalsset kann letztendlich ein Klassifikator erlernt werden. Dieser Klassifikator wird durch 10-fache Kreuzvalidierungen mit unterschiedlichen Klassifikationsparametern überprüft werden. Dabei spielen nicht nur die Gesamtgenauigkeit, sondern auch die klassenspezifischen Genauigkeiten (die User’s Accuracy und die Producer’s Accuracy) eine wichtige Rolle.
Ergebnisse und Fazit
Im Allgemeinen gelten die Ergebnisse als befriedigend. Bei der besten Kombination von Klassifikationsparametern liegt die Gesamtgenauigkeit bei ungefähr 70%. Bei Betrachtung der Ergebnisse fällt auf, dass die User’s Accuracy und die Producer’s Accuracy der Klasse Nichtwohnnutzungsgebiet von etwa 85% und 90% am genausten sind, gefolgt von denen der Klasse Diskontinuierliche Dichte Wohnsiedlung mit kleinen Unterschieden um etwa 5% bis 10%. Auf der anderen Seite liegen die User’s Accuracy und die Producer’s Accuracy der Klasse Kontinuierliche Wohnsiedlung unter 50%. Somit lässt sich feststellen, dass sich die Leistungen unterschiedlicher Klassen signifikant voneinander unterscheiden.
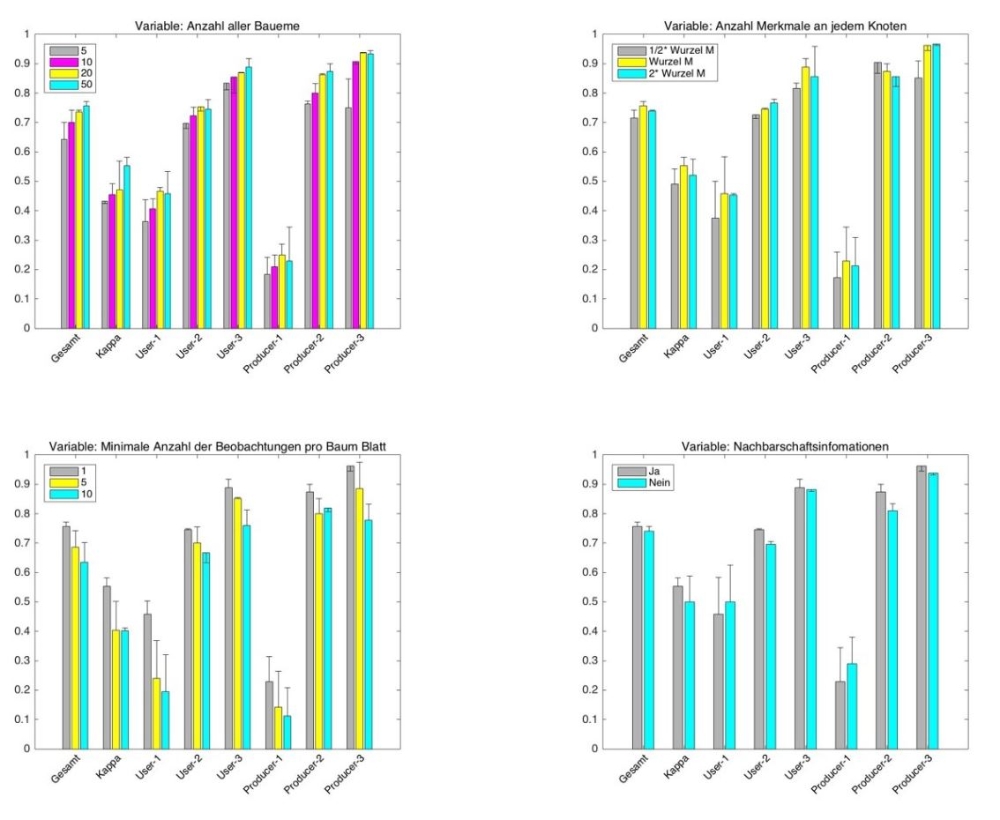
Neben den Genauigkeitsmaßen wird die Wichtigkeit der Merkmale bestimmt. Die Mehrheit der wichtigsten Merkmale bezieht sich auf die Größe und Form von Einzelgebäuden. Die statistische Kenngröße Standardabweichung stellt die Streuung eines Datensatzes dar und trägt deswegen sehr gut zur Erkennung unterschiedlicher Strukturen bei. Darüber hinaus stellt sich heraus, dass die Genauigkeiten in kleinem Maße verbessert werden, wenn nur die wichtigsten Merkmale bei der Klassifikation verwendet würden.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter