
Michael Kölle
Klassifikation hochaufgelöster LiDAR- und MVS-Punktwolken zu Monitoringzwecken
Dauer der Arbeit: 6 Monate
Abgabe: Oktober 2018
Betreuer: M.Sc. Dominik Laupheimer
Prüfer: Prof. Dr.-Ing. Norbert Haala
Motivation
Im Rahmen dieser Arbeit wurde das Ziel verfolgt, Punktwolken unterschiedlicher Erfassungsmethodik für Monitoringzwecke aufzubereiten. Die Datengrundlage hierfür wird durch Drohnenbefliegungen mittels photogrammetrischer Methoden sowie mittels Airborne Laserscanning im Rahmen eines Projektes (CRAMER et al. 2018), welches mit der Bundesanstalt für Gewässerkunde (BfG) durchgeführt wird, gestellt. In diesen beiden Punktwolken, welche sich jeweils durch eine extrem hohe räumliche Auflösung auszeichnen, sollen automatisch Bereiche selektiert werden anhand derer Senkungsmessungen des Geländes durchgeführt werden können. Die Rede ist also von Objekten, welche grundsätzlich als fest bzw. unbeweglich angenommen werden dürfen, sodass beispielsweise Vegetation hier ausgeschlossen werden kann. Eine derartige Selektion versteht sich im Prinzip als Klassifikation der Punktwolke, wodurch diese Vorarbeit geleistet wird. Ziel ist dabei, den Daten eine semantische Information zuzuordnen.
Vorgehensweise
Zum Zwecke der Klassifizierung der Punktwolken ist es in einem ersten Schritt notwendig, diese manuell in sinnvolle Klassen zu unterteilen. Hierbei wird zunächst eine relativ detailreiche Untergliederung der Szene in insgesamt 11 Klassen durchgeführt, wobei diese dann nachfolgend derart zusammengefasst werden, dass lediglich eine binäre Unterscheidung in Geeignet und Ungeeignet für Monitoring erfolgt. Unter Nutzung dieser gelabelten Referenzdaten können geeignete Klassifikatoren trainiert werden, welchen jedoch Merkmale für die einzelnen Primitive, also die einzelnen Punkte der Punktwolke, zur Verfügung gestellt werden müssen.
Sämtliche Merkmale werden sowohl für eine kugelförmige als auch eine zylindrische Nachbarschaft im Sinne einer Multiskalenanalyse für unterschiedliche Nachbarschaftsradien ausgewertet. Die Auffindung dieser Nachbarpunkte fällt aber selbst unter Nutzung räumlicher Zugriffsstrukturen, wie etwa eines K-d-Baums, extrem rechenintensiv aus. Daher wird zur Minimierung des Rechenaufwands in höheren Skalen eine zunehmend stärkere Ausdünnung der dieser Arbeit zugrunde liegenden Punktwolken durchgeführt. Dennoch erlaubt selbst dieser Ansatz aufgrund extensiver Rechenzeit kaum die Prozessierung aller erfassten Punkte, weshalb die beiden Datensätze als Kompromiss zwischen Rechenaufwand und Klassifikationsgenauigkeit auf einen Punktabstand von 30 cm unterabgetastet werden. Hieraus entstehen für das Ziel des Monitorings keine wesentlichen Einschränkungen, da hiermit lediglich die Menge potentiell geeigneter Punkte für das Deformationsmodell reduziert wird.
Die im Rahmen dieser Arbeit verwendeten Merkmale lassen sich in geometrische und nicht-geometrische Merkmale untergliedern, wobei sich gezeigt hat, dass eine Kombination dieser Merkmalsgruppen für eine erfolgreiche Klassifikation zielführend ist. Die geometrischen Merkmale behandeln dabei hauptsächlich die charakteristische Anordnung der Nachbarpunkte eines Primitivs, was insbesondere durch eigenwertbasierte und nicht-eigenwertbasierte Merkmale, welche ebenfalls die Punktverteilung berücksichtigen, erfolgt. Als besonders aussagekräftige geometrische Merkmale haben sich zudem auch höhenbasierte Merkmale herausgestellt, wie insbesondere die Höhe über Grund, aber auch Merkmale, die Eigenschaften, ausgehend von einer robust geschätzten Ebene in der Punktnachbarschaft, beschreiben. Die nicht geometrischen Merkmale behandeln insbesondere die aufgezeichnete Farbe der Primitive, wobei diese im Falle der LiDAR-Daten nachträglich aus einer eigens hierfür erzeugten photogrammetrischen Punktwolke interpoliert wird. Im LiDAR-Fall können zudem spezifische echobasierte Merkmale extrahiert werden.
Zur Klassifikation der beiden Datensätze auf Grundlage dieser Merkmale, welche im Rahmen dieser Arbeit noch getrennt erfolgt, hat sich insbesondere der Ansatz des Random-Forest-Klassifikators sowie derjenige des Multi-Branch 1D-CNN als zielführend herausgestellt.
Ergebnisse und Fazit
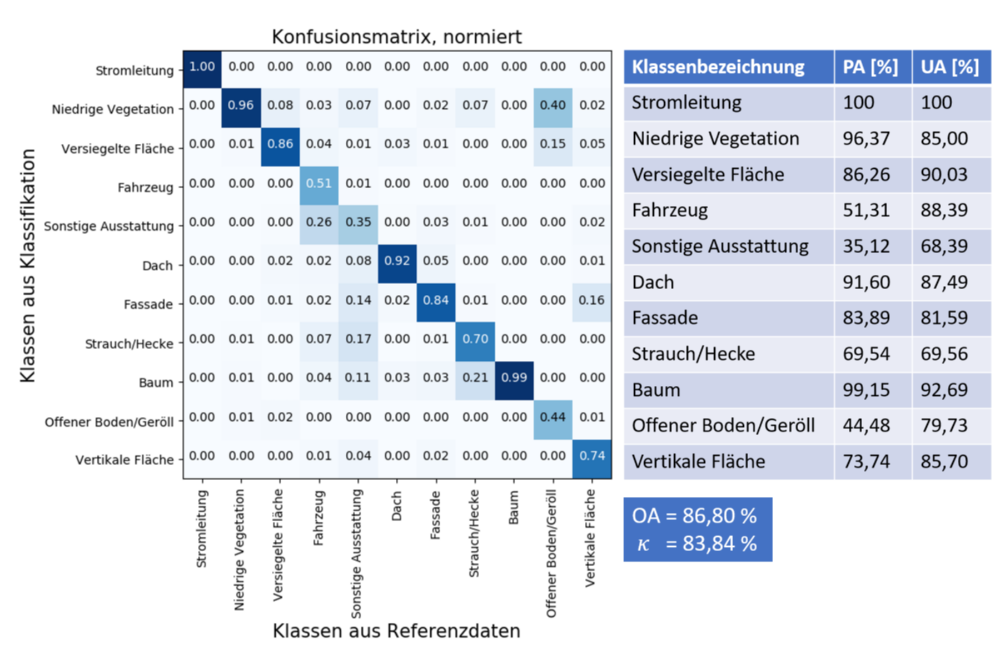
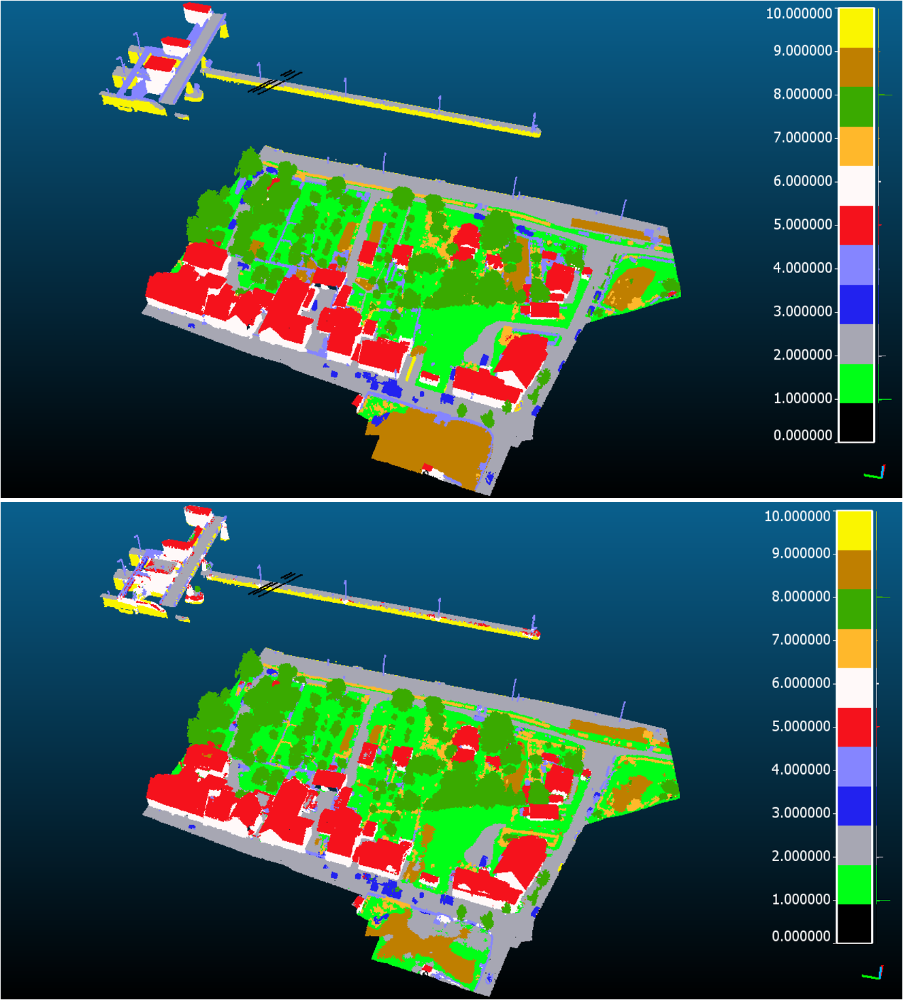
Mit dem Random-Forest-Klassifikator konnte im Falle der LiDAR-Daten für den Mehrklassenfall eine OA von 86,80% (vgl. Abbildung 1 sowie graphische Darstellung in Abbildung 2) erreicht werden und für den MVS-Datensatz eine etwas geringere OA von 81,60%. Damit sind die LiDAR-Daten für diesen Zweck zu bevorzugen.
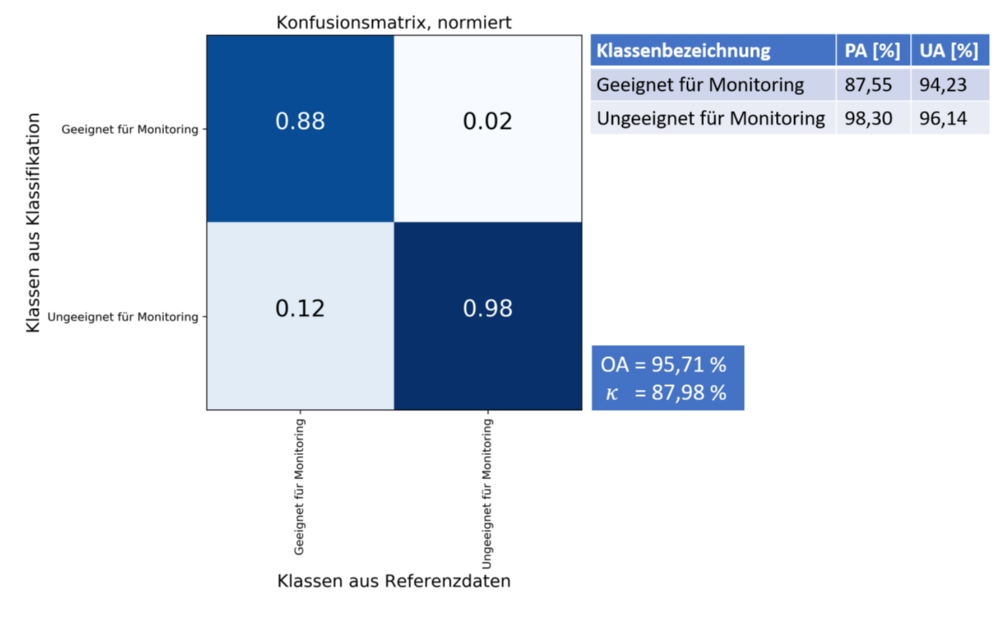
Eine binäre Klassifikation erreicht für den LiDAR-Datensatz eine OA von 95,71% (vgl. Abbildung 3 sowie graphische Darstellung in Abbildung 4) und für den MVS-Datensatz eine solche von 92,78%. Hier kann also die Klassifikationsgenauigkeit nochmals deutlich erhöht werden. Insbesondere von Bedeutung ist im Rahmen dieser Arbeit allerdings die UA für die Klasse Geeignet für Monitoring, welche 94,23% bzw. 91,29% beträgt. Das bedeutet, in beiden Fällen gehen wenige Punkte fälschlicherweise in das Deformationsmodell ein, sodass das beabsichtigte Ziel der Arbeit, der automatischen Detektion geeigneter Flächen für Monitoringzwecke, durchaus erreicht werden konnte.
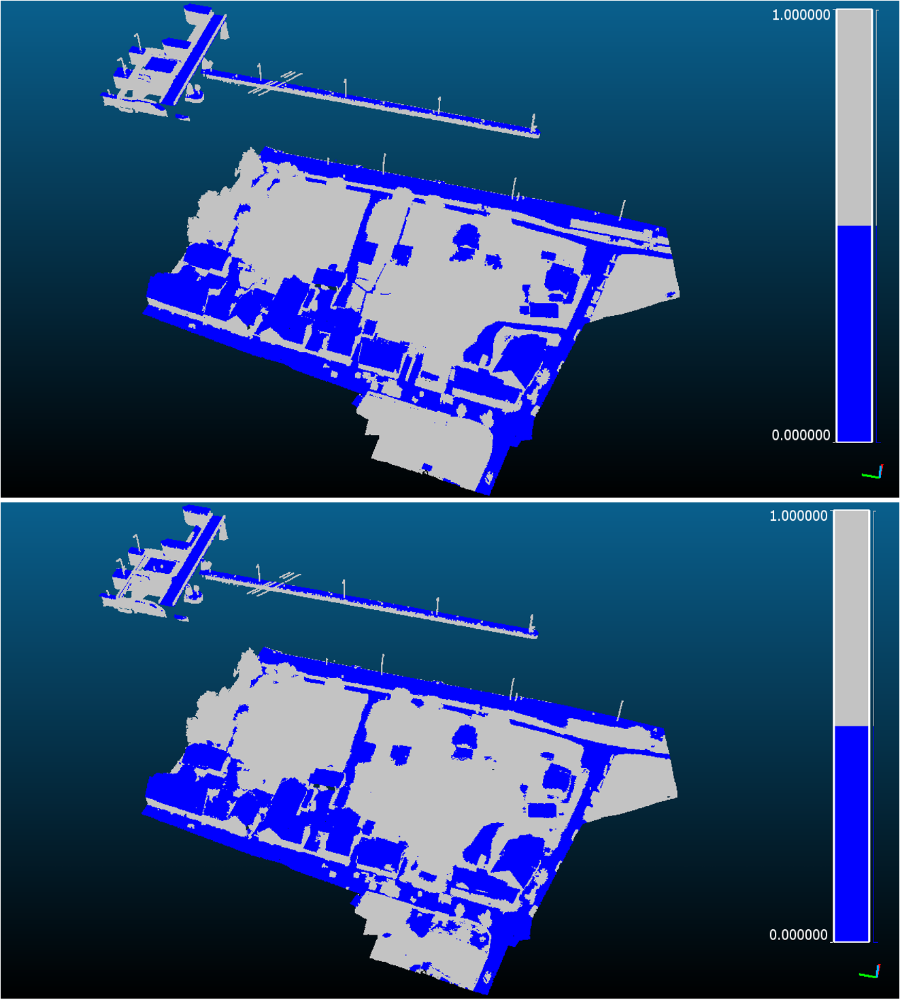
Des Weiteren werden in all diesen Fällen die Ergebnisse des Random Forest durch Regularisierungen mittels MRF und CRF nachbearbeitet, wodurch sich nur geringe Verbesserungen in der Genauigkeit ergeben und beide Regularisierungen nahezu deckungsgleiche Ergebnisse hervorbringen. Insgesamt entstehen hierdurch jedoch etwas glattere Klassifikationsergebnisse.
Als alternativer Klassifikator mit bereits sehr guter Genauigkeit hat sich im Rahmen dieser Arbeit derjenige des Multi-Branch 1D-CNN herausgestellt, wenngleich er vom Random-Forest-Klassifikator noch übertroffen wird. Dennoch zeigen die Ergebnisse dieser Arbeit, dass auch CNNs durchaus zielführend sind, und zwar speziell solche, die analog zu eher klassischen Klassifikationsansätzen, wie etwa demjenigen des Random-Forest-Klassifikators, auf Modellwissen in Form von zur Verfügung gestellten Merkmalen zurückgreifen. Nachteil dieses Verfahrens ist jedoch das für CNNs typische Erfordernis einer großen Menge an Trainingsdaten. Auch hier zeigt sich der potentielle Mehrwert der im Rahmen dieser Arbeit vorliegenden dichten Punktwolken, womit eine große Menge an Trainingsdaten zur Verfügung gestellt werden kann. Wenn nun das Problem des erheblichen Rechenaufwands für die Merkmalsgewinnung noch bewältigt werden kann, hat dieser Klassifikator das Potential, den im Rahmen dieser Arbeit genutzten Random-Forest-Klassifikator im Hinblick auf die Genauigkeit zu übertreffen.
Referenz
Cramer, M., Haala, N., Laupheimer, D., Mandlburger, G. & Havel, P., 2018: Ultra-High Precision UAV-based LiDAR and Dense Image Matching. Int. Arch. Photogr. Rem. Sens. Spat. Inf. Sci., XLII-1, 115-120.
Ansprechpartner

Michael Cramer
Dr.-Ing.Gruppenleiter Photogrammetrische Systeme