Jörg Richard Adam
Markov Marked Point Process zur Klassifizierung von Gebäuden in 2.5D-Punktwolken
Dauer der Arbeit: 6 Monate
Abgabe: Februar 2017
Betreuerin: Dr.-Ing. Susanne Becker
Prüfer: Prof. Dr.-Ing. Norbert Haala
Motivation
Der Markov Marked Point Process (MPP) ist ein statistisches Optimierungsverfahren und wurde in der aktuellen Forschung bereits dazu entwickelt, Fassadenelemente in 2D-Bilddaten zu klassifizieren. Dieser Punktprozess ist ein dynamisches Verfahren. Es kann also mit variierenden Datengrößen umgehen, was im Fall einer Klassifizierung mit iterativem Optimierungsprozess auch nötig ist. Das Verfahren kombiniert das A Priori Wissen aus generierten Trainingsdaten als Top-down-Ansatz mit den Posteriori Informationen aus den zu klassifizierenden Daten als Bottom-up-Ansatz. Das bedeutet, dass die erkannten Wahrscheinlichkeiten aus einer Vorklassifizierung der Daten mit dem Trainingswissen vieler Messungen verglichen werden, welche anzeigen, wie solche Objekte typischerweise geartet sind. Dabei werden neben Lage und Ausdehnung auch die verschiedensten Arten von Nachbarschaftsrelationen untersucht. Ziel dieser Arbeit war es nun, das bisher entwickelte Verfahren für die Fassadenklassifikation auf die Detektion von Gebäuden in 2,5D-Punktwolken-Meshes zu übertragen.
U(X) = Udata(X) + λ1 · Ugeom(X) + λ2 · Uconfig(X) + λ3 · Unum(X)
Um mit dem Klassifikator nun die attraktivste Objektkonfiguration unter Millionen zufällig erstellter Konfigurationen zu finden, ist es nötig, die Energiefunktion zu minimieren. Dies geschieht mit dem vielfach zu iterierenden Algorithmus nach Green (MCMC).
Trainingsdaten
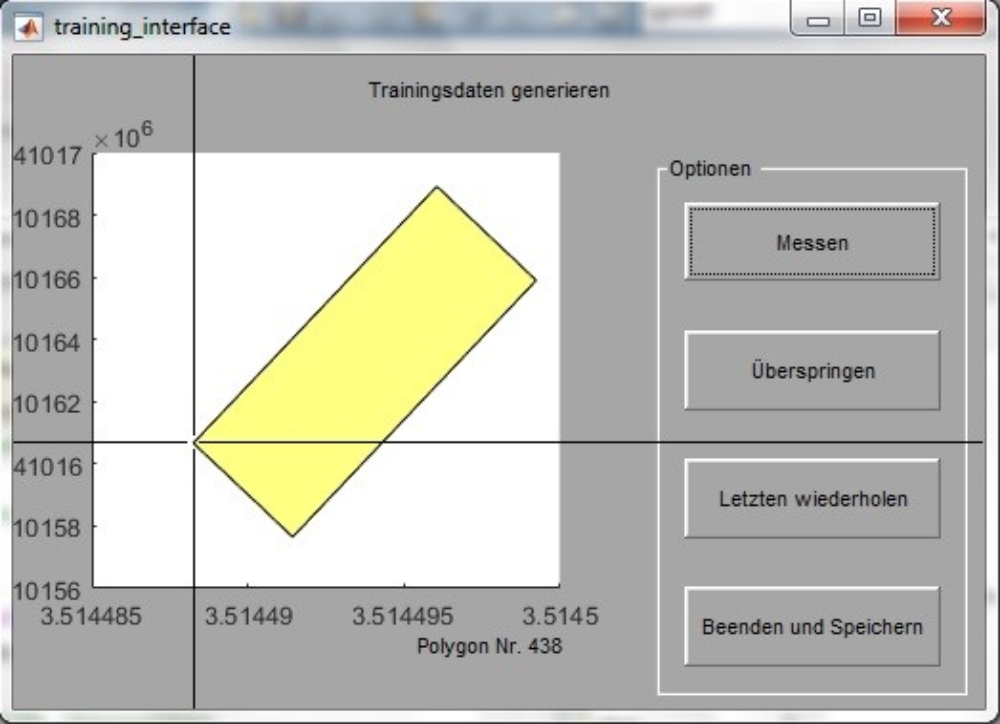
Ein selbst implementiertes Programm ermöglicht es dem Benutzer, in großen 2D-Grundrissdaten in Form von shape-Files, die das Stadtmessungsamt Stuttgart bereitgestellt hat, die Grundflächen möglichst vieler Gebäude als einfaches Rechteck zu messen (siehe Abbildung 1). All diese generalisierten Rechteck-Grundflächen werden im Verlauf des Programms auf deren typische Konfigurationen bezüglich Abstände, Schnittflächen, geometrischer Beschaffenheit und Art der Nachbarschaft berechnet und schlussendlich in Form von Histogrammen ausgegeben.
Marked Point Process
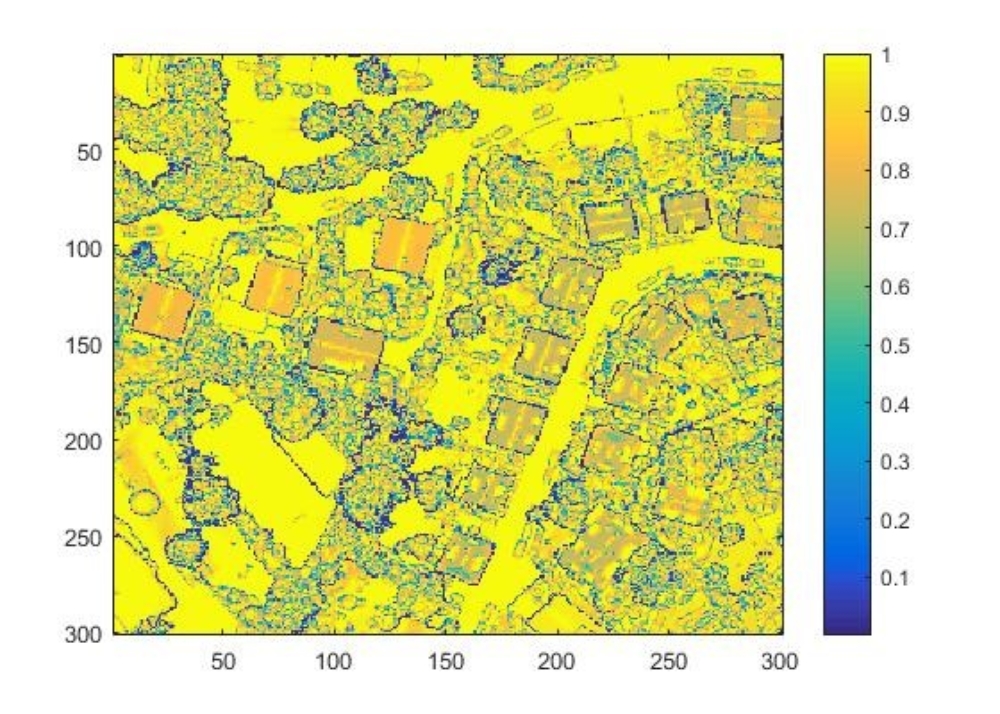
Der wichtigste Teil der Implementierung ist die Umsetzung des MPP-Algorithmus. Dieser nutzt das generierte Trainingswissen und kombiniert es mit den Informationen der Meshes. Als eigene Idee wurden die Posteriori Informationen nicht wie in der bisherigen Forschung aus einem Vorklassifikator gewonnen, sondern aus den Daten selbst. Die Höheninformationen der Knotenpunkte des Meshes wurden dazu genutzt, eine Posteriori-Matrix unabhängig von einem externen Klassifikator zu erstellen (siehe Abbildung 2).

Außerdem wurden die Normalenvektoren der Mesh-Knoten, die neben den reinen Grafik- und Geometriedaten in den .obj-Files mitgeliefert werden, dazu verwendet, die Posteriori-Wahrscheinlichkeiten zu stützen. Zu diesem Zweck kann man die normierten z-Werte der Normalenvektoren nutzen, da jene ja durch ihre Neigung zur z-Achse quasi die Neigungen in der Höhenfunktion der Meshes anzeigen (siehe Abbildung 3).
Die Ergebnisse aus beiden Matrizen werden für die Bildung der Posteriori Wahrscheinlichkeiten genutzt. Nach der Prozessierung gibt der MPP eine visuelle Präsentation der Posteriori Matrix mit den gefundenen Objekten in Lage und Ausdehnung als optimierte Konfiguration aus (siehe Abbildung 4).
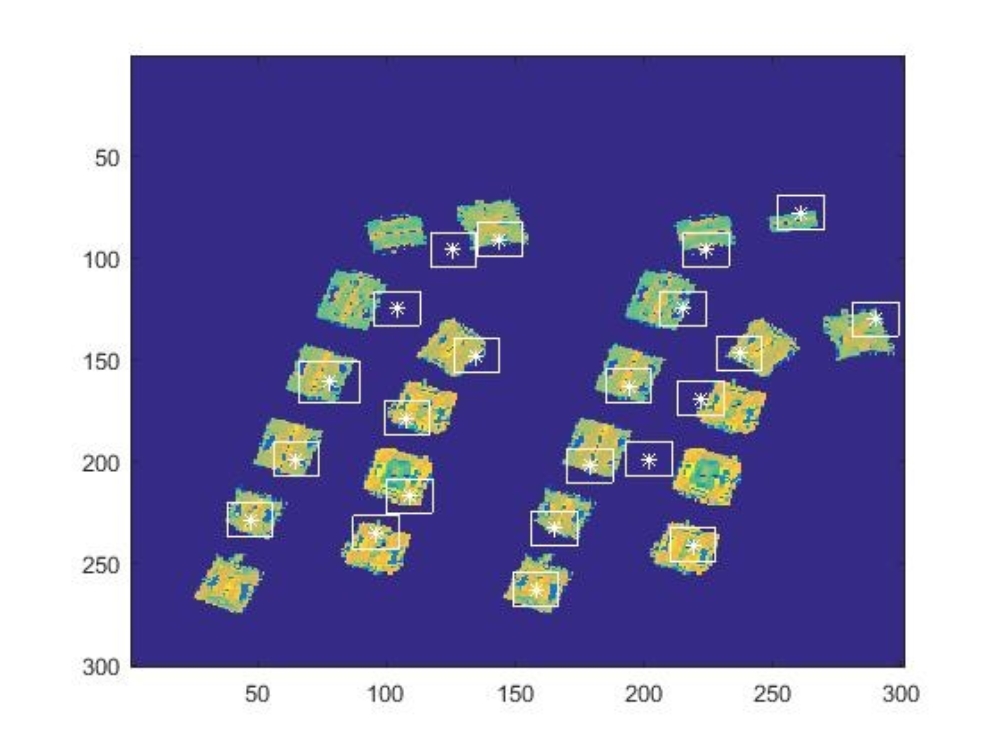
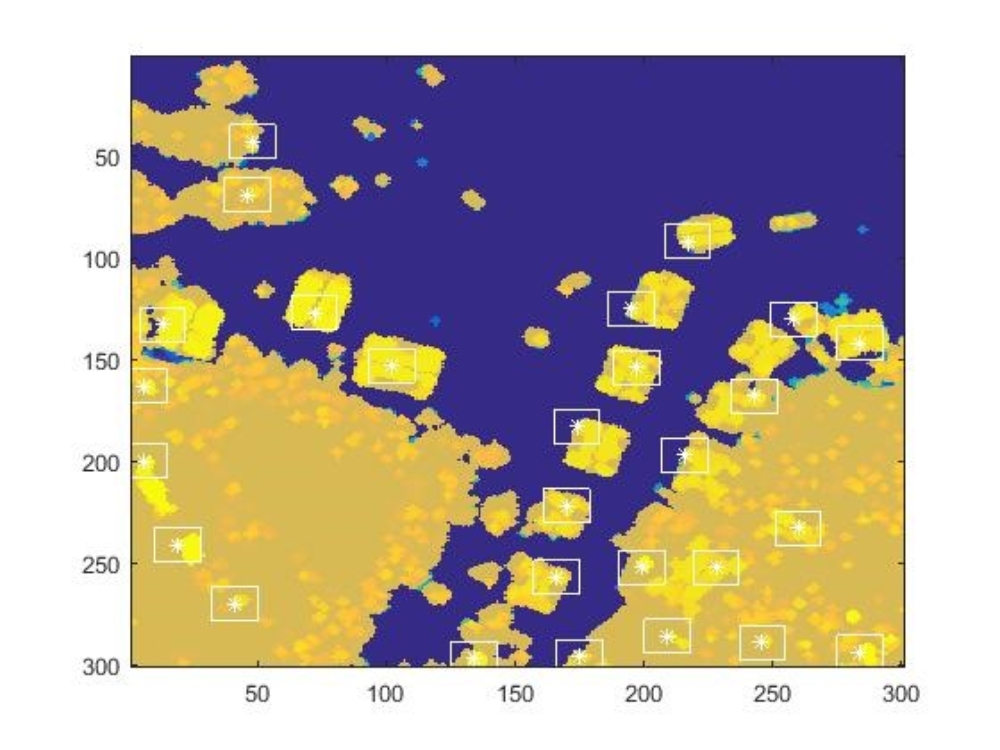
Nach weiteren Änderungen in der Gewichtung und Berechnung der Posteriori-Werte konnten durch das Verfahren deutlich mehr Gebäude erkannt werden (siehe Abbildung 5). Teilweise gelang dies auch in Bereichen mit vielen Bäumen, die grundsätzlich ein Problem darstellten.
Fazit
Der Verzicht auf einen externen Vorklassifikator war ein Wagnis, das die Unabhängigkeit des Marked Point Process von anderen Klassifikationsverfahren bewirken soll. Es bliebe daher noch zu untersuchen, wie gut der MPP wäre, wenn zur Bereitstellung der Posteriori Wahrscheinlichkeiten ein zusätzlicher Vorklassifikator verwendet würde und nicht wie hier die Wahrscheinlichkeitsinformationen aus den Höhen- und Neigungsinformationen der Mesh-Knotenpunkte abgeleitet werden würden.
Das größte Defizit dieses Verfahrens ist die Richtungsinvarianz des Objektmodells. Das Verfahren ist darauf ausgelegt, Fassadenelemente zu detektieren, die natürlich in aller Regel orthogonal zu den Hauswänden liegen, wie zum Beispiel Fenster und Türen. In einer zukünftigen Implementierung empfiehlt es sich, die Richtungsvarianz in Kombination mit einer iterationsstarken Programmiersoftware mit einzubauen. Es bietet sich hier ein interessantes Forschungsfeld mit vielen denkbaren Möglichkeiten und Ansätzen. So kann der Marked Point Process durchaus auch in anderen Bereichen zur Klassifizierung bzw. auch zur Optimierung von anderen Klassifikatoren eingesetzt werden.
Ansprechpartner

Norbert Haala
apl. Prof. Dr.-Ing.Stellvertretender Institutsleiter